
Spring Boot Aufbau-Kurs – Tag 3 von 10
📍 Deine Position im Kurs
| Tag | Thema | Status |
|---|---|---|
| 1 | Auto-Configuration & Custom Starter | Abgeschlossen ✅ |
| 2 | Spring Data JPA Basics | Abgeschlossen ✅ |
| → 3 | JPA Relationships & Queries | 👉 DU BIST HIER! |
| 4 | Spring Security – Part 1 | Kommt als nächstes |
| 5 | Spring Security – Part 2 | Noch nicht freigeschaltet |
| 6 | Caching & Serialisierung | Noch nicht freigeschaltet |
| 7 | Messaging & Email | Noch nicht freigeschaltet |
| 8 | Testing & Dokumentation | Noch nicht freigeschaltet |
| 9 | Spring Boot Actuator | Noch nicht freigeschaltet |
| 10 | Template Engines & Microservices | Noch nicht freigeschaltet |
Modul: Spring Boot Aufbau-Kurs
Dein Ziel: Komplexe Datenmodelle mit Relationships & fortgeschrittene Queries
⚡ Kurze Zusammenfassung – Das Wichtigste in 30 Sekunden
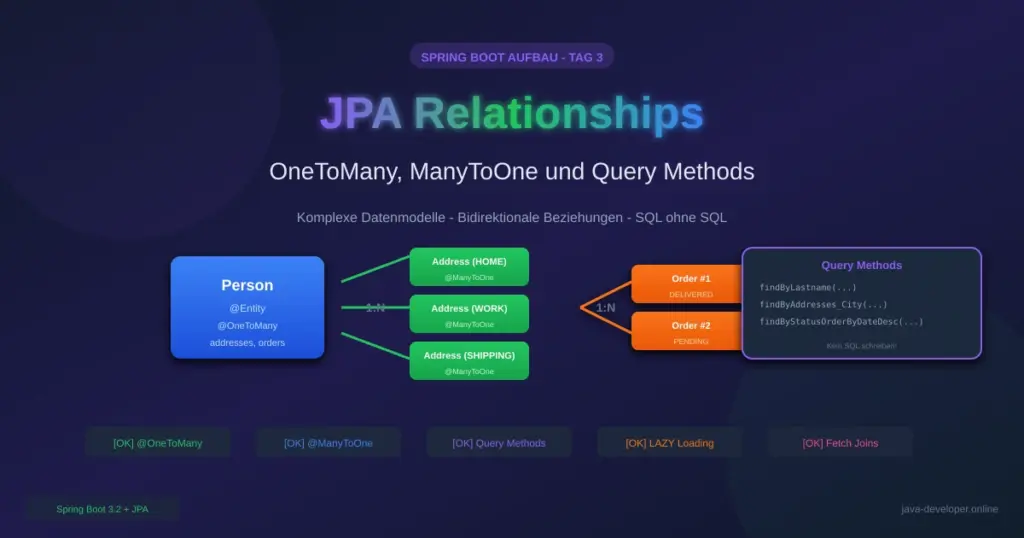
Heute erweitern wir dein Datenmodell um echte Beziehungen: Eine Person kann mehrere Adressen und Bestellungen haben. Du lernst, wie @OneToMany und @ManyToOne funktionieren, wie du bidirektionale Beziehungen synchron hältst und wie Spring Data JPA automatisch SQL aus deinen Methodennamen generiert – komplett ohne SQL zu schreiben!
Du lernst heute:
- ✅ OneToMany Relationships (Person → mehrere Adressen)
- ✅ ManyToOne Beziehungen richtig implementieren
- ✅ Bidirektionale Relationships synchron halten
- ✅ Query Methods nach Naming Convention
- ✅ LAZY vs EAGER Loading verstehen
📋 Voraussetzungen
Du brauchst:
- ✅ Tag 1 & Tag 2 abgeschlossen
- ✅ Person Entity mit @Entity, @Id verstehen
- ✅ JpaRepository nutzen können
- ✅ OneToOne Relationship (von gestern)
- ✅ MariaDB läuft und ist verbunden
Du solltest können:
- ✅ Entities erstellen
- ✅ CRUD-Operationen über Repository
- ✅ Basic JPA Annotations verstehen
Hier kannst du die Sourcen von Tag 3 runterladen!
💻 Los geht’s!
Hi Developer! 👋
Elyndra hier – heute wird es richtig spannend! Wir bauen komplexe Datenmodelle.
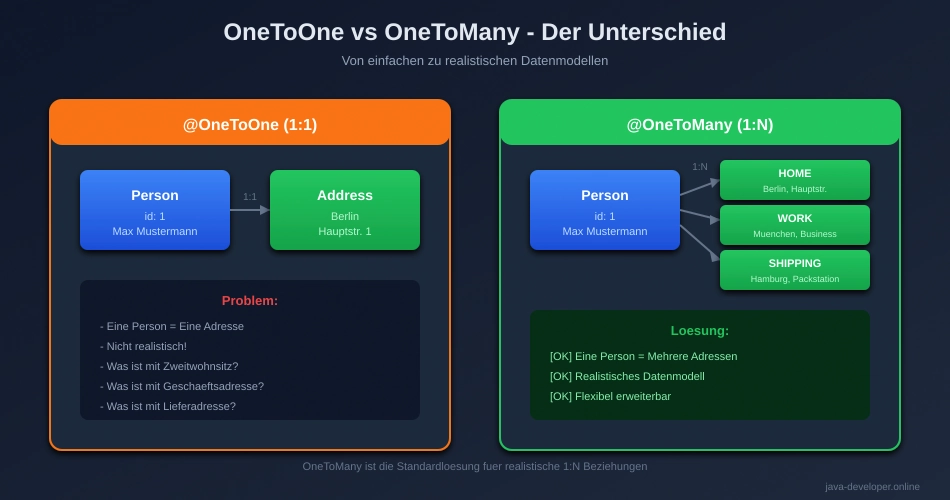
Warum OneToMany statt OneToOne?
Gestern haben wir OneToOne gelernt: Eine Person hatte genau eine Adresse. Das war einfach, aber nicht realistisch!
In der echten Welt:
- 🏠 Eine Person hat oft mehrere Adressen (Hauptwohnsitz, Zweitwohnsitz, Geschäftsadresse)
- 📦 Eine Person kann viele Bestellungen aufgeben
- 💳 Eine Person hat mehrere Zahlungsmethoden
Zeit, realistische Datenmodelle zu bauen! 🔧
🎯 Dein Lernpfad heute:
Du arbeitest heute in mehreren aufbauenden Schwierigkeitsstufen. Arbeite in deinem eigenen Tempo durch die Schritte:
🟢 GRUNDLAGEN (Schritte 1-4)
Was du lernst:
- Von OneToOne zu OneToMany migrieren
- Person mit mehreren Adressen modellieren
- @ManyToOne und @OneToMany verstehen
- Bidirectionale Relationships korrekt implementieren
- Helper-Methoden für Synchronisation
- Query Methods nach Naming Convention
Ziel: Du hast ein funktionierendes System mit Person → mehrere Adressen und kannst einfache Queries ohne SQL schreiben.
🟡 PROFESSIONAL (Schritte 5-6)
Was du lernst:
- Zweite OneToMany Relationship (Person → Orders)
- LAZY vs EAGER Loading verstehen und richtig einsetzen
- N+1 Query Problem erkennen und lösen
- Custom Queries mit @Query und JPQL
- Fetch Joins für Performance

Ziel: Du verstehst Performance-Aspekte und kannst komplexe Queries optimieren.
🔵 BONUS: Advanced Features (Schritt 7)
Was du baust:
- Pagination und Sorting
- Specifications für dynamische Queries
- EntityGraph für komplexe Fetch-Strategien
- Projection Interfaces für DTOs
Ziel: Du beherrschst Enterprise-Level JPA Features.
💡 Tipp: Die Grundlagen (🟢) sind heute besonders wichtig – Relationships sind das Fundament aller komplexen Datenmodelle. Professional (🟡) macht dich produktionsreif mit Performance-Optimierungen. Bonus (🔵) zeigt dir was in großen Enterprise-Projekten genutzt wird.
🟢 GRUNDLAGEN
Schritt 1: Von OneToOne zu OneToMany verstehen
Was du gestern gelernt hast
OneToOne: Person ↔ Address (1:1)
- Eine Person hat genau eine Adresse
- Einfach, aber nicht sehr realistisch
OneToOne: Person ←→ Address (1:1)
[Person 1] ←→ [Address 1]
Die Realität ist komplexer!
OneToMany: Person ←→ Adressen (1:N)
OneToMany: Person ←→ Adressen (1:N)
[Person 1] ←→ [Address 1]
←→ [Address 2]
←→ [Address 3]
Heute bauen wir:
- Person → mehrere Adressen (OneToMany)
- Person → mehrere Orders (OneToMany)
- Order → eine Person (ManyToOne)
🎉 AHA-Moment #1: „OneToMany ist perfekt für die reale Welt – ein Kunde hat viele Bestellungen, ein Autor viele Bücher, ein Unternehmen viele Mitarbeiter!“
Schritt 2: OneToMany – Person mit mehreren Adressen
Wir ändern unser Modell: Eine Person kann jetzt mehrere Adressen haben!
AddressType Enum erstellen
Zuerst definieren wir die Arten von Adressen, die wir unterstützen wollen.
Datei: src/main/java/com/javafleet/personmanagement/entity/AddressType.java
package com.javafleet.personmanagement.entity;
public enum AddressType {
HOME, // Hauptwohnsitz
WORK, // Geschäftsadresse
BILLING, // Rechnungsadresse
SHIPPING // Lieferadresse
}
Was passiert hier?
Ein enum ist eine spezielle Klasse für feste Wertemengen. Hier definieren wir vier mögliche Adresstypen. Das verhindert Tippfehler und gibt uns Type Safety – statt „home“ als String (könnte auch „Home“, „HOME“, „hoem“ sein) haben wir AddressType.HOME.
🎓 Lernhinweis: Enums sind perfekt für Status-Felder, Typen, Kategorien – immer wenn du eine begrenzte Menge an Optionen hast!
Address Entity anpassen
Jetzt fügen wir den Typ zur Address-Entity hinzu und erstellen die ManyToOne-Beziehung zur Person.
Datei: src/main/java/com/javafleet/personmanagement/entity/Address.java
package com.javafleet.personmanagement.entity;
import jakarta.persistence.*;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.Size;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Entity
@Table(name = "addresses")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "Straße darf nicht leer sein")
@Size(max = 100)
@Column(nullable = false, length = 100)
private String street;
@NotBlank(message = "Stadt darf nicht leer sein")
@Size(max = 50)
@Column(nullable = false, length = 50)
private String city;
@NotBlank(message = "PLZ darf nicht leer sein")
@Size(max = 10)
@Column(nullable = false, length = 10)
private String zipCode;
@Size(max = 50)
@Column(length = 50)
private String country;
// NEU: Typ der Adresse
@Enumerated(EnumType.STRING)
@Column(length = 20)
private AddressType type;
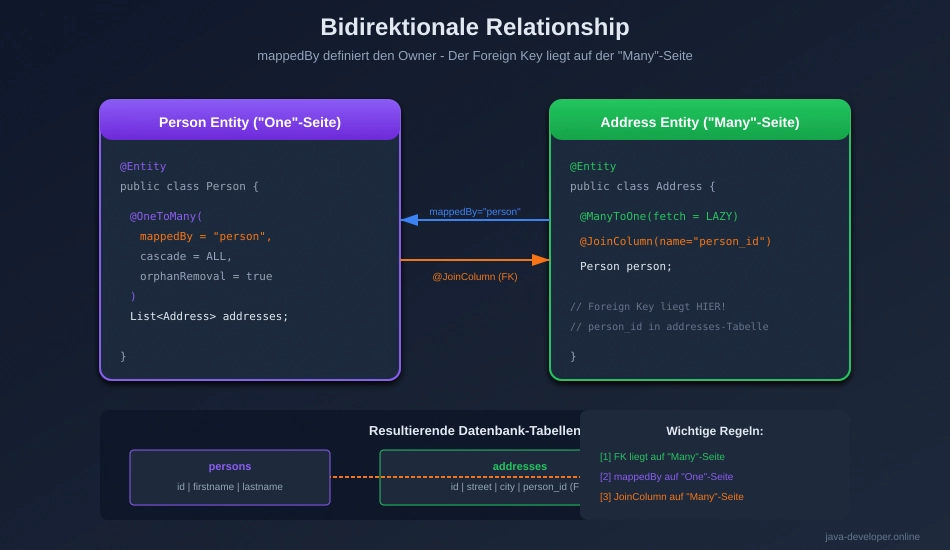
// NEU: Bidirectional ManyToOne
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "person_id")
@ToString.Exclude // Wichtig für Lombok!
private Person person;
}
Lass uns jede neue Annotation im Detail verstehen:
@Enumerated(EnumType.STRING)
@Enumerated(EnumType.STRING) @Column(length = 20) private AddressType type;
Was macht das?
@Enumerated sagt JPA, wie der Enum in der Datenbank gespeichert werden soll:
EnumType.STRING→ Speichert „HOME“, „WORK“ etc. als Text in der DatenbankEnumType.ORDINAL→ Speichert 0, 1, 2, 3 (Position im Enum) ❌ NIE VERWENDEN!
Warum STRING statt ORDINAL?
Stell dir vor, du fügst später einen neuen Typ zwischen HOME und WORK ein:
// Vorher: HOME, // 0 WORK, // 1 BILLING, // 2 // Nachher: HOME, // 0 VACATION, // 1 ← NEU! WORK, // 2 ← Jetzt 2 statt 1! BILLING, // 3 ← Jetzt 3 statt 2!
Mit ORDINAL wären plötzlich alle WORK-Adressen als VACATION markiert! 😱
Mit STRING bleibt „WORK“ immer „WORK“, egal was du hinzufügst.
🎓 Lernhinweis: IMMER EnumType.STRING verwenden, NIE ORDINAL!
@ManyToOne
@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "person_id") @ToString.Exclude private Person person;
Was macht das?
@ManyToOne definiert die „Many“-Seite einer Relationship:
- Many Addresses gehören zu One Person
- Aus Sicht der Address: „Ich gehöre zu einer Person“
Die drei Teile im Detail:
1. @ManyToOne(fetch = FetchType.LAZY)
LAZY= Person wird nicht automatisch geladen beim Laden der Address- Nur wenn du explizit
address.getPerson()aufrufst, wird die Person aus der DB geholt - Spart Performance, weil du nicht immer die Person brauchst
2. @JoinColumn(name = „person_id“)
- Erstellt eine Spalte
person_idin deraddresses-Tabelle - Diese Spalte ist ein Foreign Key zur
persons-Tabelle - Die „Many“-Seite hat immer den Foreign Key!
3. @ToString.Exclude
- Verhindert dass Lombok die
personintoString()einbaut - Wichtig bei bidirektionalen Relationships!
- Sonst:
Address.toString()→ ruftPerson.toString()→ ruftAddress.toString()→ StackOverflowError! 💥
🎓 Lernhinweis: Bei bidirektionalen Relationships IMMER @ToString.Exclude auf der „Many“-Seite verwenden!
🎉 AHA-Moment #2: „Der Foreign Key liegt immer auf der ‚Many‘-Seite – viele Adressen verweisen auf eine Person, nicht umgekehrt!“
Person Entity erweitern
Jetzt die andere Seite der Beziehung: Person hat jetzt eine Liste von Adressen.
Datei: src/main/java/com/javafleet/personmanagement/entity/Person.java
package com.javafleet.personmanagement.entity;
import jakarta.persistence.*;
import jakarta.validation.constraints.Email;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.Size;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import java.util.ArrayList;
import java.util.List;
@Entity
@Table(name = "persons")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "Vorname darf nicht leer sein")
@Size(max = 50)
@Column(nullable = false, length = 50)
private String firstname;
@NotBlank(message = "Nachname darf nicht leer sein")
@Size(max = 50)
@Column(nullable = false, length = 50)
private String lastname;
@Email(message = "Email muss valid sein")
@Column(unique = true)
private String email;
// GEÄNDERT: Von OneToOne zu OneToMany!
@OneToMany(
mappedBy = "person",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
@ToString.Exclude // Wichtig für Lombok!
private List<Address> addresses = new ArrayList<>();
// Helper-Methoden für bidirectionale Relationship
public void addAddress(Address address) {
addresses.add(address);
address.setPerson(this);
}
public void removeAddress(Address address) {
addresses.remove(address);
address.setPerson(null);
}
}
Lass uns @OneToMany im Detail verstehen:
@OneToMany Parameter erklärt
@OneToMany(
mappedBy = "person", // 1. Wer ist die andere Seite?
cascade = CascadeType.ALL, // 2. Was passiert bei Operationen?
orphanRemoval = true, // 3. Was mit "verwaisten" Entities?
fetch = FetchType.LAZY // 4. Wann laden?
)
1. mappedBy = „person“
- „Du bist nicht der Owner!“ – Address ist der Owner (hat den Foreign Key)
"person"verweist auf dasperson-Feld in derAddress-Entity- Die Relationship wird von Address.person gemappt (daher „mappedBy“)
- Ohne
mappedBywürde JPA eine zusätzliche Join-Tabelle erstellen! ❌
Regel: Die „One“-Seite hat mappedBy, die „Many“-Seite hat @JoinColumn.
2. cascade = CascadeType.ALL
- Operationen auf Person werden kaskadiert zu den Adressen
ALL= PERSIST + MERGE + REMOVE + REFRESH + DETACH
Was heißt das praktisch?
Person person = new Person("Max", "Mustermann");
Address address = new Address("Hauptstraße 1", "Berlin", "10115");
person.addAddress(address);
entityManager.persist(person);
// → Person UND Address werden gespeichert!
entityManager.remove(person);
// → Person UND alle Adressen werden gelöscht!
Andere Cascade-Optionen:
CascadeType.PERSIST→ Nur bei persist() kaskadierenCascadeType.REMOVE→ Nur bei remove() kaskadierenCascadeType.MERGE→ Nur bei merge() kaskadieren
3. orphanRemoval = true
- „Verwaiste“ Entities werden automatisch gelöscht
Was ist ein Orphan (Waise)? Eine Address ohne Person:
person.getAddresses().remove(address); // → Address ist jetzt ein Orphan (person_id = null) // → Mit orphanRemoval=true wird sie aus der DB gelöscht!
Ohne orphanRemoval:
person.getAddresses().remove(address); // → Address bleibt in DB mit person_id = null
4. fetch = FetchType.LAZY
- Adressen werden nicht automatisch geladen beim Laden der Person
- Nur wenn du
person.getAddresses()aufrufst, werden sie geholt - Wichtig für Performance!
LAZY vs EAGER:
// LAZY (Default für @OneToMany): Person person = repository.findById(1L); // SQL: SELECT * FROM persons WHERE id = 1 // Adressen werden NICHT geladen! person.getAddresses().size(); // SQL: SELECT * FROM addresses WHERE person_id = 1 // Jetzt werden Adressen geladen! // EAGER: Person person = repository.findById(1L); // SQL: SELECT * FROM persons p // LEFT JOIN addresses a ON p.id = a.person_id // WHERE p.id = 1 // Adressen werden SOFORT geladen!
🎓 Lernhinweis: Für @OneToMany ist LAZY der Default – und das ist gut so! EAGER kann zu Performance-Problemen führen (wir kommen im Professional-Teil dazu).
🎉 AHA-Moment #3: „Cascade und orphanRemoval machen mein Leben so viel einfacher – ich muss nur die Person speichern/löschen, und die Adressen folgen automatisch!“
Helper-Methoden – Warum?
public void addAddress(Address address) {
addresses.add(address); // 1. Adresse zur Liste hinzufügen
address.setPerson(this); // 2. Rückwärts-Referenz setzen!
}
public void removeAddress(Address address) {
addresses.remove(address); // 1. Adresse aus Liste entfernen
address.setPerson(null); // 2. Rückwärts-Referenz löschen!
}
Warum nicht einfach person.getAddresses().add(address)?
Bei bidirektionalen Relationships musst du beide Seiten synchron halten:
❌ Falsch:
Address address = new Address("Straße", "Stadt", "12345");
person.getAddresses().add(address);
// → address.getPerson() ist noch NULL!
// → Inkonsistenter Zustand!
✅ Richtig:
Address address = new Address("Straße", "Stadt", "12345");
person.addAddress(address);
// → address.getPerson() ist jetzt person
// → Beide Seiten konsistent!
Die Helper-Methoden garantieren:
- ✅ Beide Seiten der Relationship sind synchron
- ✅ Kein inkonsistenter Zustand möglich
- ✅ Sauberer, lesbarer Code
🎓 Lernhinweis: Bei bidirektionalen Relationships IMMER Helper-Methoden verwenden, NIE direkt die Collection manipulieren!
Schritt 3: Repository und Controller anpassen
Wir brauchen keine Änderungen am PersonRepository – es funktioniert automatisch mit der neuen Relationship!
Datei: src/main/java/com/javafleet/personmanagement/repository/PersonRepository.java
package com.javafleet.personmanagement.repository;
import com.javafleet.personmanagement.entity.Person;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
Optional<Person> findByEmail(String email);
List<Person> findByLastname(String lastname);
}
Warum funktioniert das ohne Änderungen?
JpaRepository arbeitet mit der Entity-Klasse. Alle Relationships (OneToOne, OneToMany, ManyToOne, ManyToMany) werden automatisch von JPA/Hibernate verwaltet. Du musst dich nicht um die Joins kümmern – das macht JPA für dich!
Controller für Person mit mehreren Adressen
Datei: src/main/java/com/javafleet/personmanagement/controller/PersonController.java
package com.javafleet.personmanagement.controller;
import com.javafleet.personmanagement.entity.Address;
import com.javafleet.personmanagement.entity.AddressType;
import com.javafleet.personmanagement.entity.Person;
import com.javafleet.personmanagement.repository.PersonRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api/persons")
@RequiredArgsConstructor
public class PersonController {
private final PersonRepository personRepository;
// Alle Personen abrufen
@GetMapping
public List<Person> getAllPersons() {
return personRepository.findAll();
}
// Person mit ID abrufen
@GetMapping("/{id}")
public ResponseEntity<Person> getPersonById(@PathVariable Long id) {
return personRepository.findById(id)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// Neue Person mit Adressen erstellen
@PostMapping
public Person createPerson(@RequestBody Person person) {
// Helper-Methoden synchronisieren die Relationship automatisch!
return personRepository.save(person);
}
// Adresse zu existierender Person hinzufügen
@PostMapping("/{id}/addresses")
public ResponseEntity<Person> addAddress(
@PathVariable Long id,
@RequestBody Address address) {
return personRepository.findById(id)
.map(person -> {
person.addAddress(address); // Helper-Methode!
return ResponseEntity.ok(personRepository.save(person));
})
.orElse(ResponseEntity.notFound().build());
}
}
Was ist hier neu?
Der Endpoint POST /api/persons/{id}/addresses fügt eine neue Adresse zu einer existierenden Person hinzu:
person.addAddress(address); // Helper-Methode synchronisiert beide Seiten! personRepository.save(person); // Cascade speichert auch die neue Address!
Durch cascade = CascadeType.ALL wird die neue Address automatisch gespeichert!
Testen mit cURL
Person mit mehreren Adressen erstellen:
curl -X POST http://localhost:8080/api/persons \
-H "Content-Type: application/json" \
-d '{
"firstname": "Max",
"lastname": "Mustermann",
"email": "max@example.com",
"addresses": [
{
"street": "Hauptstraße 1",
"city": "Berlin",
"zipCode": "10115",
"country": "Deutschland",
"type": "HOME"
},
{
"street": "Geschäftsweg 42",
"city": "München",
"zipCode": "80333",
"country": "Deutschland",
"type": "WORK"
}
]
}'
Adresse zu existierender Person hinzufügen:
curl -X POST http://localhost:8080/api/persons/1/addresses \
-H "Content-Type: application/json" \
-d '{
"street": "Lieferadresse 7",
"city": "Hamburg",
"zipCode": "20095",
"country": "Deutschland",
"type": "SHIPPING"
}'
Person mit allen Adressen abrufen:
curl http://localhost:8080/api/persons/1
Funktioniert es? Dann hast du deine erste OneToMany-Relationship erfolgreich implementiert! 🎉
Schritt 4: Query Methods – SQL ohne SQL schreiben!
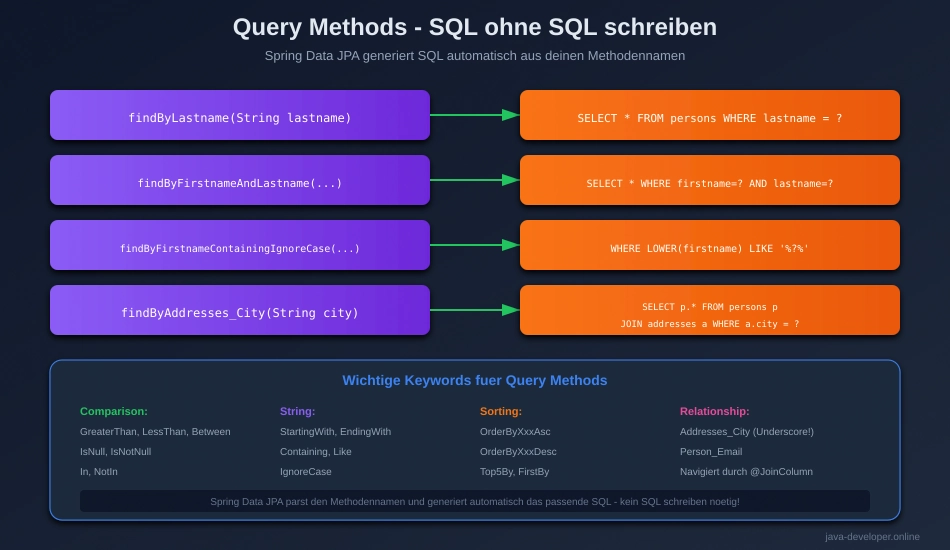
Jetzt kommt einer der coolsten Features von Spring Data JPA: Query Methods.
Du schreibst den Methodennamen, Spring Data JPA generiert automatisch das SQL!
Query Methods nach Naming Convention
Die Magie: Spring Data JPA parst deinen Methodennamen und erstellt daraus SQL:
// Methodenname: findByLastname List<Person> findByLastname(String lastname); // Wird zu SQL: // SELECT * FROM persons WHERE lastname = ?
So funktioniert’s:
- Spring Data JPA liest den Methodennamen
- Erkennt
findBy→ SELECT-Query - Erkennt
Lastname→ Das Feld aus der Person-Entity - Generiert automatisch:
SELECT * FROM persons WHERE lastname = ? - Parameter
String lastnamewird für?eingesetzt
🎉 AHA-Moment #4: „Ich kann komplexe Queries schreiben ohne SQL zu kennen! Spring Data JPA generiert das SQL automatisch aus meinen Methodennamen! Das ist unglaublich produktiv!“
PersonRepository erweitern
Datei: src/main/java/com/javafleet/personmanagement/repository/PersonRepository.java
package com.javafleet.personmanagement.repository;
import com.javafleet.personmanagement.entity.Person;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Optional;
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
// Finde nach Email (exact match)
Optional<Person> findByEmail(String email);
// Finde nach Nachname (exact match)
List<Person> findByLastname(String lastname);
// Finde nach Vorname (case-insensitive, partial match)
List<Person> findByFirstnameContainingIgnoreCase(String firstname);
// Finde nach Vor- und Nachname
List<Person> findByFirstnameAndLastname(String firstname, String lastname);
// Finde nach Nachname, sortiere nach Vorname
List<Person> findByLastnameOrderByFirstnameAsc(String lastname);
// Finde Personen mit Adresse in bestimmter Stadt
List<Person> findByAddresses_City(String city);
// Finde Personen mit bestimmtem Adresstyp
List<Person> findByAddresses_Type(AddressType type);
}
Lass uns jede Query-Methode verstehen:
findByEmail
Optional<Person> findByEmail(String email);
Generiertes SQL:
SELECT * FROM persons WHERE email = ?
Warum Optional?
- Wir erwarten maximal ein Ergebnis (email ist unique)
Optional<Person>sagt: „Kann eine Person sein, kann aber auch leer sein“- Verhindert NullPointerException!
findByLastname
List<Person> findByLastname(String lastname);
Generiertes SQL:
SELECT * FROM persons WHERE lastname = ?
Warum List?
- Mehrere Personen können denselben Nachnamen haben
- Ergebnis kann 0, 1 oder viele Personen sein
findByFirstnameContainingIgnoreCase
List<Person> findByFirstnameContainingIgnoreCase(String firstname);
Generiertes SQL:
SELECT * FROM persons WHERE LOWER(firstname) LIKE LOWER(CONCAT('%', ?, '%'))
Was macht das?
Containing→ LIKE ‚%value%‘ (Teilstring-Suche)IgnoreCase→ LOWER() auf beiden Seiten (Groß-/Kleinschreibung ignorieren)
Beispiel:
// Findet: "Maximilian", "Max", "Maximilian"
findByFirstnameContainingIgnoreCase("max");
🎓 Lernhinweis: Spring Data JPA hat aus Containing und IgnoreCase automatisch eine LIKE-Query mit LOWER() gemacht!
findByFirstnameAndLastname
List<Person> findByFirstnameAndLastname(String firstname, String lastname);
Generiertes SQL:
SELECT * FROM persons WHERE firstname = ? AND lastname = ?
Das And im Methodennamen wird zu AND in SQL!
findByAddresses_City
List<Person> findByAddresses_City(String city);
Generiertes SQL:
SELECT DISTINCT p.* FROM persons p INNER JOIN addresses a ON p.id = a.person_id WHERE a.city = ?
Was passiert hier?
Der Unterstrich _ navigiert durch die Relationship!
Addresses→ Die addresses-Liste in Person_City→ Das city-Feld in Address
Spring Data JPA erstellt automatisch den JOIN!
🎓 Lernhinweis: Mit _ kannst du durch Relationships navigieren und JPA erstellt die Joins automatisch!
Unterstützte Keywords
Spring Data JPA unterstützt viele Keywords für Query Methods:
Comparison:
findByAgeGreaterThan(int age)→age > ?findByAgeLessThan(int age)→age < ?findByAgeBetween(int start, int end)→age BETWEEN ? AND ?
String:
findByNameStartingWith(String prefix)→name LIKE 'prefix%'findByNameEndingWith(String suffix)→name LIKE '%suffix'findByNameContaining(String infix)→name LIKE '%infix%'findByNameIgnoreCase(String name)→LOWER(name) = LOWER(?)
Null:
findByEmailIsNull()→email IS NULLfindByEmailIsNotNull()→email IS NOT NULL
Boolean:
findByActiveTrue()→active = TRUEfindByActiveFalse()→active = FALSE
Collections:
findByAgeIn(List<Integer> ages)→age IN (?)findByAgeNotIn(List<Integer> ages)→age NOT IN (?)
Sorting:
findByLastnameOrderByFirstnameAsc(String lastname)→... ORDER BY firstname ASC
Limiting:
findTop5ByOrderByCreatedAtDesc()→... LIMIT 5findFirstByEmail(String email)→... LIMIT 1
🔗 Offizielle Dokumentation:
Spring Data JPA – Query Methods Reference
Testen der Query Methods
Erweitere den Controller mit Such-Endpunkten:
Datei: src/main/java/com/javafleet/personmanagement/controller/PersonController.java (erweitern)
// Suche nach Nachname
@GetMapping("/search/by-lastname")
public List<Person> searchByLastname(@RequestParam String lastname) {
return personRepository.findByLastname(lastname);
}
// Suche nach Email
@GetMapping("/search/by-email")
public ResponseEntity<Person> searchByEmail(@RequestParam String email) {
return personRepository.findByEmail(email)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// Suche Personen mit Adresse in Stadt
@GetMapping("/search/by-city")
public List<Person> searchByCity(@RequestParam String city) {
return personRepository.findByAddresses_City(city);
}
Testen mit cURL:
# Person nach Nachname finden curl "http://localhost:8080/api/persons/search/by-lastname?lastname=Mustermann" # Person nach Email finden curl "http://localhost:8080/api/persons/search/by-email?email=max@example.com" # Personen mit Adresse in Stadt finden curl "http://localhost:8080/api/persons/search/by-city?city=Berlin"
Kein einziges SQL Statement geschrieben! 🎉
🟡 PROFESSIONAL
Schritt 5: Zweite OneToMany – Person → Orders
Jetzt fügen wir eine zweite OneToMany-Relationship hinzu: Eine Person kann viele Bestellungen haben!
OrderStatus Enum
Datei: src/main/java/com/javafleet/personmanagement/entity/OrderStatus.java
package com.javafleet.personmanagement.entity;
public enum OrderStatus {
PENDING, // Wartend
CONFIRMED, // Bestätigt
SHIPPED, // Versandt
DELIVERED, // Zugestellt
CANCELLED // Storniert
}
Order Entity
Datei: src/main/java/com/javafleet/personmanagement/entity/Order.java
package com.javafleet.personmanagement.entity;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Entity
@Table(name = "orders")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String orderNumber;
@Column(nullable = false)
private BigDecimal price;
@Enumerated(EnumType.STRING)
@Column(nullable = false, length = 20)
private OrderStatus status;
@Column(nullable = false)
private LocalDateTime orderDate;
// ManyToOne zur Person
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "person_id")
@ToString.Exclude
private Person person;
// Automatisch Datum setzen beim Erstellen
@PrePersist
protected void onCreate() {
if (orderDate == null) {
orderDate = LocalDateTime.now();
}
if (status == null) {
status = OrderStatus.PENDING;
}
}
}
Was ist @PrePersist?
@PrePersist
protected void onCreate() {
if (orderDate == null) {
orderDate = LocalDateTime.now();
}
}
@PrePersist ist ein Lifecycle Callback – eine Methode, die automatisch aufgerufen wird bevor die Entity in die Datenbank gespeichert wird.
Lifecycle Callbacks:
@PrePersist→ Vor dem ersten Speichern@PostPersist→ Nach dem ersten Speichern@PreUpdate→ Vor jedem Update@PostUpdate→ Nach jedem Update@PreRemove→ Vor dem Löschen@PostRemove→ Nach dem Löschen
Praktische Verwendung:
- Timestamps automatisch setzen (createdAt, updatedAt)
- Default-Werte setzen
- Validierung vor dem Speichern
- Audit-Logs erstellen
🎓 Lernhinweis: @PrePersist ist perfekt für Felder die immer einen Wert haben sollen, aber nicht vom User gesetzt werden!
Person Entity erweitern
Füge die orders-Liste zur Person hinzu:
Datei: src/main/java/com/javafleet/personmanagement/entity/Person.java (erweitern)
@Entity
@Table(name = "persons")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// ... firstname, lastname, email ...
// Adressen (bereits vorhanden)
@OneToMany(
mappedBy = "person",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
@ToString.Exclude
private List<Address> addresses = new ArrayList<>();
// NEU: Orders
@OneToMany(
mappedBy = "person",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
@ToString.Exclude
private List<Order> orders = new ArrayList<>();
// Helper-Methoden für Adressen (bereits vorhanden)
public void addAddress(Address address) {
addresses.add(address);
address.setPerson(this);
}
public void removeAddress(Address address) {
addresses.remove(address);
address.setPerson(null);
}
// NEU: Helper-Methoden für Orders
public void addOrder(Order order) {
orders.add(order);
order.setPerson(this);
}
public void removeOrder(Order order) {
orders.remove(order);
order.setPerson(null);
}
}
Jetzt hat Person zwei OneToMany-Relationships:
- Person → mehrere Adressen
- Person → mehrere Orders
Beide nutzen das gleiche Pattern:
mappedBy→ andere Seite ist Ownercascade = ALL→ Operationen werden kaskadiertorphanRemoval = true→ Verwaiste Entities werden gelöschtfetch = LAZY→ Nicht automatisch laden- Helper-Methoden → Synchronisation garantiert
Schritt 6: LAZY vs EAGER & das N+1 Problem
Jetzt kommen wir zu einem der wichtigsten Performance-Themen in JPA: LAZY vs EAGER Loading und das N+1 Query Problem.
LAZY Loading (Default für @OneToMany)
Was ist LAZY?
- Related Entities werden nicht automatisch geladen
- Nur wenn du sie explizit abrufst
- Gut für Performance, weil nicht immer alles geladen wird
Beispiel:
Person person = personRepository.findById(1L).get(); // SQL: SELECT * FROM persons WHERE id = 1 // addresses und orders werden NICHT geladen! System.out.println(person.getFirstname()); // Kein zusätzliches SQL person.getAddresses().size(); // SQL: SELECT * FROM addresses WHERE person_id = 1 // Jetzt werden addresses geladen! person.getOrders().size(); // SQL: SELECT * FROM orders WHERE person_id = 1 // Jetzt werden orders geladen!
Vorteile:
- ✅ Schneller initial Load
- ✅ Weniger Daten übertragen
- ✅ Flexibel – du lädst nur was du brauchst
Nachteile:
- ❌ Mehrere separate Queries (kann zum N+1 Problem führen)
- ❌
LazyInitializationExceptionaußerhalb einer Transaction
EAGER Loading
Was ist EAGER?
- Related Entities werden sofort mit geladen
- Immer, auch wenn du sie nicht brauchst
- Standard für @ManyToOne und @OneToOne
Beispiel:
@ManyToOne(fetch = FetchType.EAGER) // EAGER explizit setzen private Person person; Address address = addressRepository.findById(1L).get(); // SQL: SELECT a.*, p.* // FROM addresses a // LEFT JOIN persons p ON a.person_id = p.id // WHERE a.id = 1 // Person wird SOFORT mit geladen!
Vorteile:
- ✅ Alles in einer Query
- ✅ Keine
LazyInitializationException - ✅ Kann in manchen Fällen effizienter sein
Nachteile:
- ❌ Immer alle Daten, auch wenn nicht benötigt
- ❌ Kann zu riesigen Queries führen
- ❌ Bei @OneToMany: Cartesian Product Problem!
Das N+1 Query Problem
Das Problem:
Wenn du eine Liste von Personen lädst und dann für jede Person die Adressen abrufst, entstehen N+1 Queries:
List<Person> persons = personRepository.findAll();
// Query 1: SELECT * FROM persons
for (Person person : persons) {
System.out.println(person.getAddresses().size());
// Query 2: SELECT * FROM addresses WHERE person_id = 1
// Query 3: SELECT * FROM addresses WHERE person_id = 2
// Query 4: SELECT * FROM addresses WHERE person_id = 3
// ... für jede Person eine Query!
}
Bei 100 Personen → 101 Queries! 😱
Das ist das N+1 Problem:
- 1 Query für alle Personen
- N Queries für die Related Entities (eine pro Person)
- = N+1 Queries
Lösung 1: Fetch Joins mit @Query
Lade alles in einer Query mit einem Fetch Join:
Datei: src/main/java/com/javafleet/personmanagement/repository/PersonRepository.java (erweitern)
package com.javafleet.personmanagement.repository;
import com.javafleet.personmanagement.entity.Person;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Optional;
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
// Query Methods (bereits vorhanden)
Optional<Person> findByEmail(String email);
List<Person> findByLastname(String lastname);
// NEU: Custom Query mit Fetch Join
@Query("SELECT DISTINCT p FROM Person p LEFT JOIN FETCH p.addresses")
List<Person> findAllWithAddresses();
@Query("SELECT DISTINCT p FROM Person p " +
"LEFT JOIN FETCH p.addresses " +
"LEFT JOIN FETCH p.orders " +
"WHERE p.id = :id")
Optional<Person> findByIdWithAll(@Param("id") Long id);
}
Was macht @Query?
@Query("SELECT DISTINCT p FROM Person p LEFT JOIN FETCH p.addresses")
List<Person> findAllWithAddresses();
- Du schreibst eine JPQL-Query (Java Persistence Query Language)
- JPQL ist wie SQL, aber mit Entities statt Tabellen
JOIN FETCHsagt: „Lade die Related Entities in derselben Query“DISTINCTentfernt Duplikate (durch den Join entstehen mehrere Zeilen pro Person)
Das generierte SQL:
SELECT DISTINCT p.*, a.* FROM persons p LEFT JOIN addresses a ON p.id = a.person_id
Jetzt:
List<Person> persons = personRepository.findAllWithAddresses();
// Nur 1 Query für alle Personen MIT allen Adressen!
for (Person person : persons) {
System.out.println(person.getAddresses().size());
// Kein zusätzliches SQL mehr!
}
Von N+1 Queries → 1 Query! 🎉
🎓 Lernhinweis: JOIN FETCH ist die Standardlösung für das N+1 Problem. Nutze es immer wenn du weißt dass du die Related Entities brauchst!
🎉 AHA-Moment #5: „Mit Fetch Joins kann ich das N+1 Problem lösen und alle Daten in einer Query laden – perfekt für Performance!“
OrderRepository mit Query Methods
Datei: src/main/java/com/javafleet/personmanagement/repository/OrderRepository.java
package com.javafleet.personmanagement.repository;
import com.javafleet.personmanagement.entity.Order;
import com.javafleet.personmanagement.entity.OrderStatus;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
import java.math.BigDecimal;
import java.util.List;
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
// Finde nach Status
List<Order> findByStatus(OrderStatus status);
// Finde nach Person ID
List<Order> findByPersonId(Long personId);
// Finde nach Person Email
List<Order> findByPersonEmail(String email);
// Finde wo Preis größer als
List<Order> findByPriceGreaterThan(BigDecimal price);
// Finde nach Status und sortiere nach Datum
List<Order> findByStatusOrderByOrderDateDesc(OrderStatus status);
// Finde nach Person und Status
List<Order> findByPersonIdAndStatus(Long personId, OrderStatus status);
// Finde die neuesten 10 Orders
List<Order> findTop10ByOrderByOrderDateDesc();
// Custom Query mit Fetch Join
@Query("SELECT o FROM Order o JOIN FETCH o.person WHERE o.status = :status")
List<Order> findByStatusWithPerson(@Param("status") OrderStatus status);
}
Auch hier nutzen wir Query Methods ohne SQL zu schreiben!
🔵 BONUS: Advanced Features
Schritt 7: Pagination, Specifications, EntityGraph & Projection Interfaces
💡 Elyndra hier: Diese Features nutze ich täglich in Enterprise-Projekten. Du brauchst sie nicht sofort auswendig zu kennen – aber du solltest wissen dass sie existieren und wofür man sie einsetzt!
7.1 Pagination & Sorting
Das Problem ohne Pagination:
java
// Gefährlich bei großen Datenmengen! List<Person> alle = personRepository.findAll(); // → Lädt 100.000 Personen auf einmal in den Speicher. Tschüss, Heap! 💥
Die Lösung: Pageable
java
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
Page<Person> findByLastname(String lastname, Pageable pageable);
}
java
// Controller:
@GetMapping
public Page<Person> getAllPersons(
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size,
@RequestParam(defaultValue = "lastname") String sortField,
@RequestParam(defaultValue = "asc") String sortDir) {
Sort sort = sortDir.equalsIgnoreCase("asc")
? Sort.by(sortField).ascending()
: Sort.by(sortField).descending();
Pageable pageable = PageRequest.of(page, size, sort);
return personRepository.findAll(pageable);
}
⚠️ Häufiger Fehler: Nicht
sort[0]direkt als Feldname verwenden wenn der Parameter"lastname,asc"als ganzes reinkommt – Spring sucht sonst nach einem Feld namens"lastname,asc"und wirft eine Exception. Feld und Richtung immer als separate Parameter übergeben!
Was gibt Page<T> zurück?
json
{
"content": [...], // Die eigentlichen Daten
"totalElements": 243, // Gesamtanzahl Datensätze
"totalPages": 25, // Gesamtanzahl Seiten
"number": 0, // Aktuelle Seite (0-basiert)
"size": 10, // Einträge pro Seite
"first": true, // Erste Seite?
"last": false // Letzte Seite?
}
🎉 AHA-Moment: „Page<T> gibt mir nicht nur die Daten sondern auch alle Metadaten für eine saubere UI-Pagination – kein manuelles Zählen nötig!“
7.2 Specifications – Dynamische Queries
Das Problem:
java
// Willst du nach Name ODER Stadt ODER beidem filtern? // Ohne Specifications: if/else Chaos oder viele Repository-Methoden List<Person> findByLastname(String lastname); List<Person> findByCity(String city); List<Person> findByLastnameAndCity(String lastname, String city); // → Explodiert bei 5+ Filteroptionen!
Die Lösung: Specifications
java
public class PersonSpecifications {
public static Specification<Person> hasLastname(String lastname) {
return (root, query, cb) ->
lastname == null ? null : cb.equal(root.get("lastname"), lastname);
}
public static Specification<Person> hasAddressInCity(String city) {
return (root, query, cb) -> {
if (city == null) return null;
Join<Person, Address> addresses = root.join("addresses");
return cb.equal(addresses.get("city"), city);
};
}
}
java
// Repository muss JpaSpecificationExecutor implementieren:
@Repository
public interface PersonRepository extends JpaRepository<Person, Long>,
JpaSpecificationExecutor<Person> {
}
java
// Verwendung – kombinierbar wie Lego:
List<Person> persons = personRepository.findAll(
hasLastname("Mustermann").and(hasAddressInCity("Berlin"))
);
// Nur nach Stadt filtern:
List<Person> persons = personRepository.findAll(
hasAddressInCity("München")
);
🎓 Lernhinweis: Der Schlüssel ist dass jede Specification null zurückgeben kann wenn der Parameter nicht gesetzt ist – Spring Data ignoriert dann dieses Kriterium automatisch. Das macht dynamische Suchformulare elegant.
🎉 AHA-Moment: „Specifications sind wie Bausteine – ich kombiniere nur was ich gerade brauche, ohne für jede Kombination eine eigene Repository-Methode zu schreiben!“
7.3 EntityGraph – N+1 Problem lösen
Kurze Wiederholung – das N+1 Problem:
java
// LAZY Loading – klingt gut, versteckt aber eine Falle:
List<Person> persons = personRepository.findAll();
// SQL: SELECT * FROM persons → 1 Query
for (Person p : persons) {
p.getAddresses().size();
// SQL: SELECT * FROM addresses WHERE person_id = ?
// → Für JEDE Person eine eigene Query!
}
// Bei 100 Personen: 1 + 100 = 101 Queries! Das ist das N+1 Problem.
Lösung 1: Fetch Join (aus Professional-Teil)
java
@Query("SELECT DISTINCT p FROM Person p LEFT JOIN FETCH p.addresses WHERE p.id = :id")
Optional<Person> findByIdWithAddresses(@Param("id") Long id);
Lösung 2: EntityGraph – Annotation-basiert, wiederverwendbar
java
@EntityGraph(attributePaths = {"addresses", "orders"})
@Query("SELECT p FROM Person p WHERE p.id = :id")
Optional<Person> findByIdWithAll(@Param("id") Long id);
EntityGraph vs. Fetch Join – wann was?
| EntityGraph | Fetch Join | |
|---|---|---|
| Definition | Annotation | JPQL-Query |
| Wiederverwendbar | ✅ Ja | ❌ Pro Query |
| Flexibilität | Mittel | Hoch |
| Lesbarkeit | Sehr gut | Gut |
| Empfehlung | Standard-Use-Cases | Komplexe Queries |
🎓 Lernhinweis: EntityGraph ist mein täglicher Begleiter für Standard-Fälle. Fetch Join kommt zum Einsatz wenn ich die Query sowieso schreibe und gleichzeitig die Relationship laden will.
7.4 Projection Interfaces – DTOs ohne Klassen
Das Problem mit vollen Entities:
java
// Du brauchst für eine Liste nur Name und Email // Aber du lädst die ganze Person inkl. aller Relationships: List<Person> persons = personRepository.findAll(); // → id, firstname, lastname, email, birthDate, addresses, orders, ... // → Alles im Speicher, obwohl du 90% nicht brauchst!
Die alte Lösung – Hilfsklassen (du kennst das 😉):
java
// Extra DTO-Klasse, manuelles Mapping – funktioniert, aber aufwändig
public class PersonSummaryDTO {
private String firstname;
private String email;
// Konstruktor, Getter, Setter...
}
Die elegante Lösung: Projection Interface
Einfach ein Interface definieren – keine Klasse, kein Mapping:
java
public interface PersonSummary {
String getFirstname();
String getLastname();
String getEmail();
}
java
// Repository gibt direkt das Interface zurück:
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
List<PersonSummary> findByLastname(String lastname);
}
Spring generiert zur Laufzeit einen Proxy der nur die benötigten Felder aus der Datenbank holt. Das generierte SQL:
sql
-- Ohne Projection: alles laden SELECT p.id, p.firstname, p.lastname, p.email, p.birth_date, ... FROM persons p -- Mit Projection: nur was das Interface braucht SELECT p.firstname, p.lastname, p.email FROM persons p WHERE p.lastname = ?
Drei Varianten im Überblick:
1. Interface-based (einfachste Form):
java
public interface PersonSummary {
String getFirstname();
String getEmail();
}
List<PersonSummary> findByLastname(String lastname);
2. Class-based mit Record (wenn du Methoden brauchst):
java
public record PersonSummary(String firstname, String email) {
// Methoden möglich!
public String getDisplayName() {
return firstname + " <" + email + ">";
}
}
@Query("SELECT new com.javafleet.personmanagement.dto.PersonSummary(p.firstname, p.email) FROM Person p")
List<PersonSummary> findAllSummaries();
3. Dynamic Projection – eine Query, mehrere Typen:
java
// Repository:
<T> List<T> findByLastname(String lastname, Class<T> type);
// Aufruf – du entscheidest zur Laufzeit welche Projektion:
List<PersonSummary> summaries = repo.findByLastname("Müller", PersonSummary.class);
List<Person> full = repo.findByLastname("Müller", Person.class);
Wann welche Variante?
| Interface-based | Class-based | Dynamic | |
|---|---|---|---|
| Aufwand | Minimal | Gering | Minimal |
| Methoden möglich | ❌ Nein | ✅ Ja | ❌ Nein |
| Nested Projections | ✅ Ja | ❌ Nein | ✅ Ja |
| Empfehlung | Standard | Mit Logik | Flexible APIs |
Nested Projections – sogar Relationships projizieren:
java
public interface PersonWithCity {
String getFirstname();
AddressSummary getAddresses(); // Nested!
interface AddressSummary {
String getCity();
}
}
🎓 Lernhinweis: Projection Interfaces sind einer der schnellsten Wins beim Refactoring von Legacy-Code. Bestehende Queries die zu viel laden auf Projections umstellen – weniger Speicher, weniger SQL, kein manuelles Mapping.
🎉 AHA-Moment: „Ein Interface statt einer Klasse – Spring macht den Rest.“
Zusammenfassung Schritt 7
| Feature | Einsatz | Aufwand |
|---|---|---|
| Pagination | Große Datensätze seitenweise laden | Gering |
| Specifications | Dynamische Suchformulare | Mittel |
| EntityGraph | N+1 Problem lösen, wiederverwendbar | Gering |
| Projection Interface | Nur benötigte Felder laden, kein DTO-Mapping | Minimal |
💬 Elyndra’s Fazit: Diese vier Features erkenne ich in jedem gut gewarteten Enterprise-Projekt. Sie sind nicht spektakulär – aber sie machen den Unterschied zwischen Code der unter Last kollabiert und Code der läuft.
✅ Checkpoint: Hast du Tag 3 geschafft?
Grundlagen (🟢):
- [ ] Du verstehst den Unterschied OneToOne vs OneToMany
- [ ] Du hast Person mit mehreren Adressen implementiert
- [ ] Du kennst @ManyToOne und mappedBy
- [ ] Du hast Helper-Methoden für bidirectionale Relationships
- [ ] Du kannst @ToString.Exclude richtig einsetzen
- [ ] Du hast Query Methods nach Naming Convention geschrieben
- [ ] Deine Queries funktionieren ohne SQL
Professional (🟡):
- [ ] Du verstehst LAZY vs EAGER Loading
- [ ] Du kennst das N+1 Query Problem
- [ ] Du hast @Query mit JPQL genutzt
- [ ] Du hast Fetch Joins für Performance implementiert
- [ ] Du verstehst @PrePersist und Lifecycle Callbacks
Bonus (🔵):
- [ ] Du hast Pagination gesehen
- [ ] Du kennst Specifications
- [ ] Du hast EntityGraph kennengelernt
- [ ] Du weißt wie Projection Interfaces funktionieren
Alles ✅? Du bist bereit für Tag 4!
Nicht alles funktioniert?
- Überprüfe ob beide Seiten der Relationship synchron sind
- Nutze die Helper-Methoden (
addAddress,addOrder) - Kontrolliere @ToString.Exclude auf beiden Seiten
- Lade das komplette Projekt unten herunter
🔥 Elyndras Real Talk:
Weißt du, Relationships in JPA sind wie… menschliche Beziehungen. Am Anfang denkst du, es ist einfach: OneToOne, fertig. Aber dann merkst du, die Realität ist komplexer. Menschen haben mehrere Adressen, mehrere Rollen, mehrere Verbindungen.
Und genau wie im echten Leben musst du bei bidirektionalen Relationships beide Seiten synchron halten. Eine Seite allein zu aktualisieren führt zu inkonsistentem Zustand – in der Datenbank UND im Leben.
Ich habe neulich mit Marcus über Beziehungskomplexität gesprochen. Er meinte, manchmal sind die komplizierten Datenmodelle einfacher zu verstehen als echte Gefühle. Vielleicht hat er recht. In der Datenbank gibt es klare Regeln: CascadeType, orphanRemoval, FetchType. Im Leben? Da gibt’s kein Schema.
Aber das ist ein Thema für einen anderen Ort. Für private logs und Herz Schmerz. Wenn du verstehen willst, was ich meine, such mal nach diesen Begriffen. Aber Vorsicht – es wird emotional. 🔒
Keep coding, keep learning. 💙
❓ FAQ (Häufige Fragen)
Q: Was ist der Unterschied zwischen @OneToMany und @ManyToOne?
A: Das sind die zwei Seiten derselben Relationship! @OneToMany steht auf der „One“-Seite (Person), @ManyToOne auf der „Many“-Seite (Address). Zusammen bilden sie eine bidirektionale Relationship.
Q: Warum @ToString.Exclude?
A: Bei bidirektionalen Relationships würde toString() sonst endlos hin- und herspringen (Person → Address → Person → …) und einen StackOverflowError werfen!
Q: Was passiert bei Brownfield-Projekten mit existierenden Relationships?
A: Bei existierenden Datenbanken NIEMALS ddl-auto=update nutzen! Nutze Flyway-Migrations um Relationships hinzuzufügen. Ein späterer Tag behandelt Flyway für Brownfield-Szenarien!
Q: Wann EAGER statt LAZY Loading?
A: Fast nie! LAZY ist der Default und sollte fast immer genutzt werden. EAGER nur wenn du 100% sicher bist dass die Related Entities IMMER gebraucht werden.
Q: Wie verhindere ich das N+1 Query Problem?
A: Nutze Fetch Joins in @Query (JOIN FETCH) oder EntityGraphs. Das haben wir im Professional-Teil behandelt!
Q: Warum Helper-Methoden statt direkt die Collection manipulieren?
A: Bei bidirektionalen Relationships musst du beide Seiten synchron halten. Helper-Methoden (addAddress, removeAddress) garantieren das. Ohne sie riskierst du inkonsistente Zustände!
Q: Was macht ihr bei persönlichen Problemen zwischen den Projekten?
A: Das ist… kompliziert. Manche Geschichten gehören nicht in Tech-Blogs. Die gehören zu Herz Schmerz und private logs. Aber das ist ein anderes Kapitel. 🔒
Spring Boot Aufbau - Tag 3
JPA Relationships & Queries
📅 Nächster Kurstag: Tag 4
Morgen im Kurs / Nächster Blogbeitrag:
„Tag 4: Spring Security – Part 1 – Authentication & Authorization“
Was du lernen wirst:
- Spring Security Grundlagen
- Authentication vs Authorization
- UserDetailsService implementieren
- Password Encoding mit BCrypt
- Login/Logout Mechanismen
- Method Security mit @PreAuthorize
Warum wichtig? Ohne Security ist deine API offen für jeden! Spring Security schützt deine Endpoints und Daten vor unauthorisierten Zugriffen.
Voraussetzung: Tag 3 abgeschlossen
Du hast 30% des Kurses geschafft! 💪
Alle Blogbeiträge dieser Serie:
👉 Spring Boot Aufbau-Kurs – Komplette Übersicht
📥 Download & Ressourcen
Projekt zum Download:
👉 Tag3-Spring-Boot-Aufbau-JPA-Relationships.zip (GitHub-Link folgt unten)
Was ist im ZIP enthalten:
- ✅ Komplettes Maven-Projekt mit Relationships
- ✅ Person mit mehreren Adressen und Orders
- ✅ Alle Query Methods implementiert
- ✅ Test-Daten SQL-Script
- ✅ cURL-Testskript
Projekt starten:
# Projekt klonen oder ZIP entpacken cd Tag3-Spring-Boot-Aufbau-JPA-Relationships mvn spring-boot:run # Testen curl http://localhost:8080/api/persons
Probleme? Schreib mir: elyndra@java-developer.online
Das war Tag 3 vom Spring Boot Aufbau-Kurs!
Du kannst jetzt:
- ✅ OneToMany und ManyToOne Relationships implementieren
- ✅ Bidirectionale Relationships korrekt synchronisieren
- ✅ Helper-Methoden für Relationship-Management schreiben
- ✅ @ToString.Exclude für Infinite Loops einsetzen
- ✅ Query Methods ohne SQL schreiben
- ✅ @PrePersist für automatische Defaults nutzen
- ✅ Komplexe Datenmodelle mit mehreren Relationships bauen
- ✅ Das N+1 Problem erkennen und mit Fetch Joins lösen
Morgen geht’s um Security – wir schützen deine API! 🔒
Keep coding, keep learning! 💙
Tag 4 erscheint morgen. Bis dahin: Happy Coding!
„Relationships sind das Herzstück jeder Datenbank – genau wie im echten Leben!“ – Elyndra Valen
📚 Das könnte dich auch interessieren
Tags: #SpringBoot #JPA #Relationships #OneToMany #ManyToOne #QueryMethods #Hibernate #Tutorial #Tag3