
🗺️ Deine Position im Kurs
| Tag | Thema | Status |
|---|---|---|
| 1 | Auto-Configuration & Custom Starter | ✅ Abgeschlossen |
| → 2 | Spring Data JPA Basics | 👉 DU BIST HIER! |
| 3 | JPA Relationships & Queries | 📜 Kommt als nächstes |
| 4 | Spring Security Part 1 – Authentication | 🔒 Noch nicht freigeschaltet |
| 5 | Spring Security Part 2 – Authorization | 🔒 Noch nicht freigeschaltet |
| 6 | Spring Boot Caching | 🔒 Noch nicht freigeschaltet |
| 7 | Messaging & Email | 🔒 Noch nicht freigeschaltet |
| 8 | Testing & Dokumentation | 🔒 Noch nicht freigeschaltet |
| 9 | Spring Boot Actuator | 🔒 Noch nicht freigeschaltet |
| 10 | Template Engines & Microservices | 🔒 Noch nicht freigeschaltet |
Modul: Spring Boot Aufbau (10 Arbeitstage)
Dein Ziel: Von In-Memory ArrayList zur echten Datenbank mit MariaDB
📋 Voraussetzungen für diesen Tag
Du brauchst:
- ✅ Tag 1 abgeschlossen (Auto-Configuration & Custom Starter)
- ✅ Spring Boot Basic Kurs abgeschlossen
- ✅ Grundverständnis von REST APIs
- ✅ Java JDK 17+ installiert
- ✅ IDE deiner Wahl (IntelliJ, Eclipse, VS Code)
Optional (hilft beim Verständnis):
- SQL-Grundkenntnisse (SELECT, INSERT, UPDATE, DELETE)
- Verständnis von relationalen Datenbanken
📥 [Download Starter-Projekt] – damit kannst du direkt loslegen!
⚡ Was du heute baust
Heute migrieren wir eine Person-Management REST API von In-Memory ArrayList zu echter Datenbank-Persistierung. Du lernst die JPA-Basics: Entities, Repositories, Service-Layer und wie Spring Boot die komplexe JDBC-Arbeit für dich übernimmt.
Dein Erfolgserlebnis heute:
Du speicherst eine Person in der Datenbank, startest die App neu – und die Person ist immer noch da! 🎉
🎯 Dein Ziel
Am Ende des Tages kannst du:
- ✅ Den Unterschied zwischen In-Memory und Database-Persistierung erklären
- ✅ H2 und MariaDB mit Spring Boot verbinden
- ✅ JPA Entities mit Annotations erstellen (@Entity, @Id, @Column)
- ✅ JpaRepository nutzen ohne SQL zu schreiben
- ✅ Service-Layer nach Best Practice implementieren
- ✅ REST Controller mit CRUD-Operationen bauen
- ✅ Die Datenbank direkt ansehen und verstehen was Hibernate macht
🟢 GRUNDLAGEN – Die Basis verstehen
Schritt 1: Von ArrayList zu JPA – Das Problem
Hi Developer! 👋
Elyndra hier – heute lernen wir Spring Data JPA!
Das Problem kennst du bereits
Aus dem Java SE Kurs weißt du: ArrayList im RAM → Daten weg nach Neustart. Die Lösung? Eine relationale Datenbank!
Du kennst bereits:
- ✅ SQL (SELECT, INSERT, UPDATE, DELETE)
- ✅ Relationale Datenbanken
- ✅ Primary Keys, Foreign Keys
- ✅ Das Problem mit ArrayList-Persistierung
Heute lernst du:
- ✅ Wie Spring Boot das mit JPA automatisiert
- ✅ Entities statt SQL-Statements
- ✅ Repositories statt JDBC-Code
- ✅ Kein manuelles SQL mehr schreiben!
Schritt 2: Spring Data JPA – Die Magie verstehen
Früher (Java SE mit JDBC):
// Verbindung aufbauen
Connection conn = DriverManager.getConnection(url, user, password);
// Statement vorbereiten
PreparedStatement stmt = conn.prepareStatement(
"INSERT INTO persons (firstname, lastname, email) VALUES (?, ?, ?)");
stmt.setString(1, "Max");
stmt.setString(2, "Mustermann");
stmt.setString(3, "max@example.com");
// Ausführen
stmt.executeUpdate();
// Aufräumen
stmt.close();
conn.close();
Das waren 9 Zeilen Code nur um EINE Person zu speichern!
Heute (Spring Data JPA):
Person person = new Person("Max", "Mustermann", "max@example.com");
personRepository.save(person); // DAS WAR'S!
2 Zeilen statt 9 Zeilen – und Spring Boot macht im Hintergrund:
- ✅ Datenbank-Verbindung automatisch
- ✅ SQL automatisch generieren
- ✅ Tabellen automatisch erstellen
- ✅ Connection Pool automatisch verwalten
- ✅ Transaction Management automatisch
Franz-Martin sagt immer:
„1995 haben wir noch alles manuell mit JDBC gemacht. JPA ist wie von Assembler zu Java – eine Abstraktionsebene höher, viel produktiver!“
Was ist JPA?
JPA steht für Jakarta Persistence API. Das ist eine Spezifikation (ein Standard), wie Java-Objekte in Datenbanken gespeichert werden. Hibernate ist eine Implementierung dieser Spezifikation – und Spring Boot nutzt Hibernate unter der Haube!
Schritt 3: Projekt Setup – Dependencies hinzufügen
Öffne deine pom.xml und stelle sicher, dass diese Dependencies drin sind:
<dependencies>
<!-- Spring Boot Starter Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Starter Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- H2 Database (zum Lernen) -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- MariaDB Driver (später) -->
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Validation -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
</dependencies>
Was ist das?
spring-boot-starter-data-jpabringt JPA/Hibernate mith2ist eine In-Memory-Datenbank (perfekt zum Lernen!)mariadb-java-clientist der Treiber für MariaDB (nutzen wir später)spring-boot-starter-validationfür Bean Validation
Speichern nicht vergessen! Danach: Maven reload
Schritt 4: H2 In-Memory Datenbank konfigurieren
Wir starten mit H2 – einer In-Memory-Datenbank, die perfekt zum Lernen ist!
Warum erst H2, dann MariaDB?
H2 Vorteile:
- ✅ Keine Installation nötig – läuft automatisch mit Spring Boot
- ✅ Startet sofort
- ✅ Perfekt zum Lernen und Testen
- ✅ Schnell und einfach
MariaDB später:
- ✅ Echte Production-Datenbank
- ✅ Daten bleiben nach Neustart erhalten
- ✅ Professionelles Setup
Configuration mit Profiles
Wie im Spring Boot Basic Kurs gelernt: Wir arbeiten mit Spring Profiles!
Datei: src/main/resources/application.properties
# Active Profile spring.profiles.active=h2 # Server Configuration server.port=8080
Datei: src/main/resources/application-h2.properties
# H2 In-Memory Database spring.datasource.url=jdbc:h2:mem:persondb spring.datasource.driver-class-name=org.h2.Driver spring.datasource.username=sa spring.datasource.password= # H2 Console (zum Debugging) spring.h2.console.enabled=true spring.h2.console.path=/h2-console # JPA / Hibernate Configuration spring.jpa.hibernate.ddl-auto=create-drop spring.jpa.show-sql=true spring.jpa.properties.hibernate.format_sql=true # Logging logging.level.org.hibernate.SQL=DEBUG logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
Was bedeutet das?
jdbc:h2:mem:persondb= In-Memory-Datenbank mit Name „persondb“create-drop= Tabellen werden beim Start erstellt, beim Stop gelöschtshow-sql=true= SQL-Statements werden in der Console angezeigt (super zum Lernen!)format_sql=true= SQL wird schön formatiert
Das wars! Spring Boot lädt automatisch application-h2.properties wenn das h2-Profil aktiv ist.
🎉 AHA-Moment #1: „Ich brauche KEINE Datenbank zu installieren! H2 läuft einfach mit Spring Boot mit!“
Schritt 5: Erste Entity erstellen – Person
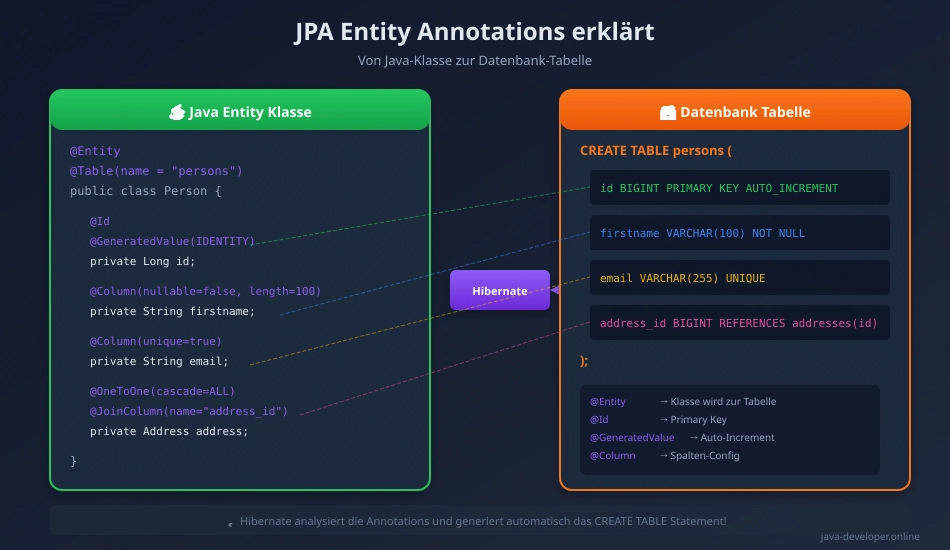
Jetzt wird’s spannend! Wir erstellen unsere erste Entity – das ist eine Java-Klasse, die eine Datenbank-Tabelle repräsentiert.
Erstelle: src/main/java/com/example/demo/model/Person.java
package com.example.demo.model;
import jakarta.persistence.*;
import jakarta.validation.constraints.Email;
import jakarta.validation.constraints.NotBlank;
@Entity
@Table(name = "persons")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "Vorname darf nicht leer sein")
@Column(nullable = false, length = 100)
private String firstname;
@NotBlank(message = "Nachname darf nicht leer sein")
@Column(nullable = false, length = 100)
private String lastname;
@Email(message = "Email muss gültig sein")
@Column(unique = true, length = 150)
private String email;
// Konstruktoren
public Person() {
// JPA braucht einen Default-Konstruktor!
}
public Person(String firstname, String lastname, String email) {
this.firstname = firstname;
this.lastname = lastname;
this.email = email;
}
// Getter und Setter
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getFirstname() {
return firstname;
}
public void setFirstname(String firstname) {
this.firstname = firstname;
}
public String getLastname() {
return lastname;
}
public void setLastname(String lastname) {
this.lastname = lastname;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
Was passiert hier? Lass uns jede Annotation verstehen:
@Entity
- Sagt Spring/Hibernate: „Das ist eine Entity, erstelle eine Tabelle dafür!“
- Hibernate erstellt automatisch eine Tabelle namens
person(oder du gibst mit @Table einen eigenen Namen an)
@Table(name = „persons“)
- Überschreibt den Tabellennamen
- Ohne das wäre die Tabelle „person“ (Singular), wir wollen „persons“ (Plural)
@Id
- Markiert das Feld als Primary Key
- Jede Entity MUSS eine @Id haben!
@GeneratedValue(strategy = GenerationType.IDENTITY)
- Die Datenbank vergibt die ID automatisch (Auto-Increment)
- Du musst keine IDs manuell setzen!
@Column(nullable = false, length = 100)
- Definiert Eigenschaften der Datenbank-Spalte
nullable = false= Feld ist Pflicht (NOT NULL)length = 100= VARCHAR(100)unique = true= Wert muss eindeutig sein (z.B. Email)
@NotBlank & @Email
- Das ist Bean Validation (nicht JPA!)
- Prüft die Werte BEVOR sie in die Datenbank gehen
- Wenn ungültig → Exception, kein SQL wird ausgeführt
Wichtig: JPA braucht einen Default-Konstruktor (ohne Parameter)! Hibernate nutzt Reflection um Objekte zu erstellen.
🎉 AHA-Moment #2: „Ich definiere nur eine Java-Klasse mit Annotations – Hibernate erstellt automatisch die Datenbank-Tabelle mit allen Spalten!“
Schritt 6: Repository erstellen – Datenbank-Zugriff ohne SQL
Jetzt kommt der magische Teil: Das Repository!
Erstelle: src/main/java/com/example/demo/repository/PersonRepository.java
package com.example.demo.repository;
import com.example.demo.model.Person;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
// Spring Data JPA generiert die Implementierung automatisch!
// Custom Query Methods (Optional - kommen später)
Optional<Person> findByEmail(String email);
}
STOPP! Was ist das?
Das ist ein Interface – keine Klasse! Und es hat keine Implementierung!
Wie funktioniert das?
Spring Data JPA erstellt zur Laufzeit automatisch eine Implementierung für dich! Du musst NUR das Interface definieren!
Was bekommst du automatisch?
save(person)– Speichert eine PersonfindById(id)– Findet Person by IDfindAll()– Findet alle PersonendeleteById(id)– Löscht Person by IDcount()– Zählt alle Personen- Und viele mehr!
JpaRepository<Person, Long>
Person= Entity-TypLong= Typ der ID
Optional<Person>
- Ein Container der entweder eine Person enthält ODER leer ist
- Verhindert NullPointerExceptions!
🎉 AHA-Moment #3: „Ich schreibe NUR ein Interface – Spring Data JPA implementiert ALLE CRUD-Methoden automatisch! Ich muss KEIN SQL schreiben!“
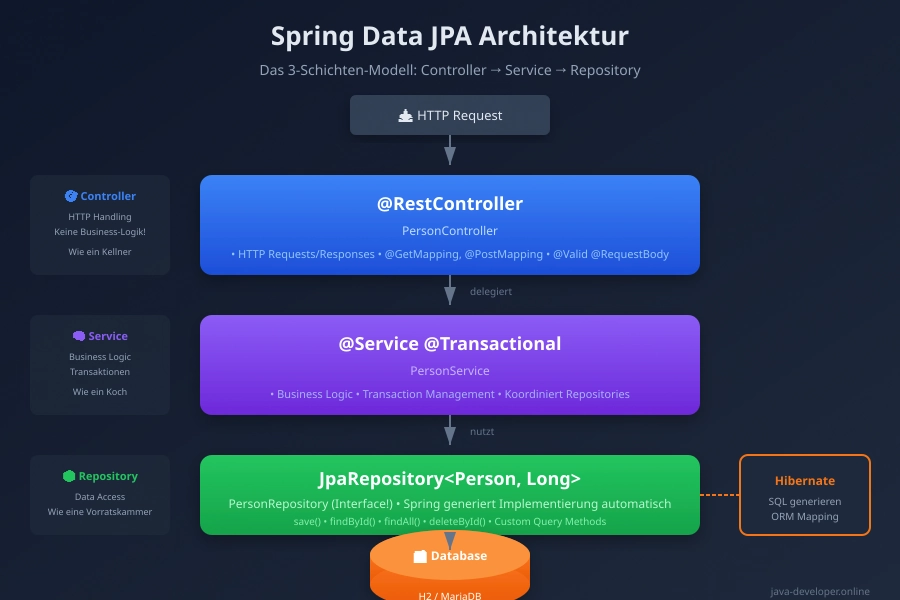
Schritt 7: Service-Layer erstellen – Business-Logik
Jetzt bauen wir den Service-Layer. Warum brauchen wir einen Service?
Separation of Concerns:
- Controller = nimmt HTTP-Requests entgegen, gibt HTTP-Responses zurück
- Service = enthält Business-Logik, koordiniert Repositories
- Repository = spricht mit der Datenbank
Erstelle: src/main/java/com/example/demo/service/PersonService.java
package com.example.demo.service;
import com.example.demo.model.Person;
import com.example.demo.repository.PersonRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Optional;
@Service
@Transactional
public class PersonService {
private final PersonRepository personRepository;
@Autowired
public PersonService(PersonRepository personRepository) {
this.personRepository = personRepository;
}
// Alle Personen abrufen
public List<Person> getAllPersons() {
return personRepository.findAll();
}
// Person by ID abrufen
public Optional<Person> getPersonById(Long id) {
return personRepository.findById(id);
}
// Person erstellen
public Person createPerson(Person person) {
// Hier könnte Business-Logik stehen
// z.B. Email-Duplikat-Check, Validierung, etc.
return personRepository.save(person);
}
// Person aktualisieren
public Person updatePerson(Long id, Person personDetails) {
Person person = personRepository.findById(id)
.orElseThrow(() -> new RuntimeException("Person not found with id " + id));
person.setFirstname(personDetails.getFirstname());
person.setLastname(personDetails.getLastname());
person.setEmail(personDetails.getEmail());
return personRepository.save(person);
}
// Person löschen
public void deletePerson(Long id) {
personRepository.deleteById(id);
}
}
Was passiert hier?
@Service
- Markiert diese Klasse als Service-Komponente
- Spring erstellt automatisch eine Instanz (Bean)
@Transactional
- Alle Methoden laufen in einer Datenbank-Transaktion
- Bei Fehler: Rollback (Änderungen werden rückgängig gemacht)
- Bei Erfolg: Commit (Änderungen werden gespeichert)
Constructor Injection
@Autowiredsagt Spring: „Gib mir ein PersonRepository“- Spring injiziert automatisch das Repository
- Das ist besser als Field Injection (
@Autowireddirekt am Feld)!
Optional<Person>
- Bei
findById: Person kann existieren ODER nicht - Mit Optional vermeidest du NullPointerExceptions
orElseThrow()
- Wenn Person nicht gefunden → Exception werfen
- Das ist besser als
nullzurückzugeben!
🎉 AHA-Moment #4: „Der Service koordiniert die Business-Logik und nutzt das Repository für Datenbank-Zugriff. Der Controller wird dadurch schlank und fokussiert!“
Schritt 8: REST Controller erstellen – Die API
Jetzt bauen wir den REST Controller – die Schnittstelle für HTTP-Requests!
Erstelle: src/main/java/com/example/demo/controller/PersonController.java
package com.example.demo.controller;
import com.example.demo.model.Person;
import com.example.demo.service.PersonService;
import jakarta.validation.Valid;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api/persons")
public class PersonController {
private final PersonService personService;
@Autowired
public PersonController(PersonService personService) {
this.personService = personService;
}
// GET /api/persons - Alle Personen abrufen
@GetMapping
public List<Person> getAllPersons() {
return personService.getAllPersons();
}
// GET /api/persons/{id} - Person by ID abrufen
@GetMapping("/{id}")
public ResponseEntity<Person> getPersonById(@PathVariable Long id) {
return personService.getPersonById(id)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// POST /api/persons - Person erstellen
@PostMapping
public ResponseEntity<Person> createPerson(@Valid @RequestBody Person person) {
Person created = personService.createPerson(person);
return ResponseEntity.status(HttpStatus.CREATED).body(created);
}
// PUT /api/persons/{id} - Person aktualisieren
@PutMapping("/{id}")
public ResponseEntity<Person> updatePerson(
@PathVariable Long id,
@Valid @RequestBody Person personDetails
) {
try {
Person updated = personService.updatePerson(id, personDetails);
return ResponseEntity.ok(updated);
} catch (RuntimeException e) {
return ResponseEntity.notFound().build();
}
}
// DELETE /api/persons/{id} - Person löschen
@DeleteMapping("/{id}")
public ResponseEntity<Void> deletePerson(@PathVariable Long id) {
personService.deletePerson(id);
return ResponseEntity.noContent().build();
}
}
Was passiert hier?
@RestController
- Kombination aus @Controller und @ResponseBody
- Alle Methoden geben automatisch JSON zurück
@RequestMapping(„/api/persons“)
- Basis-URL für alle Endpunkte
- Alle Methoden beginnen mit
/api/persons
@GetMapping, @PostMapping, @PutMapping, @DeleteMapping
- Definiert HTTP-Methoden
- GET = Daten abrufen
- POST = Neue Daten erstellen
- PUT = Daten aktualisieren
- DELETE = Daten löschen
@PathVariable
- Nimmt Werte aus der URL
/api/persons/5→ id = 5
@RequestBody
- Nimmt JSON aus dem HTTP-Body
- Spring konvertiert JSON automatisch zu Person-Objekt!
@Valid
- Aktiviert Bean Validation
- Wenn Person ungültig → 400 Bad Request
ResponseEntity<Person>
- Erlaubt uns HTTP-Status-Codes zu setzen
- 200 OK, 201 Created, 404 Not Found, etc.
🎉 AHA-Moment #5: „Der Controller ist super schlank! Er delegiert alles an den Service und kümmert sich nur um HTTP-Requests/Responses!“
Schritt 9: Testen – Deine erste Person speichern!
Starte die Anwendung:
mvn spring-boot:run
Schaue in die Console – du siehst:
Hibernate: create table persons (
id bigint generated by default as identity,
email varchar(150),
firstname varchar(100) not null,
lastname varchar(100) not null,
primary key (id)
)
Das ist das SQL das Hibernate für dich generiert hat! Du hast kein SQL geschrieben – Hibernate hat es aus deiner Entity erstellt!
Jetzt teste die API mit cURL:
1. Person erstellen (POST):
curl -X POST http://localhost:8080/api/persons \
-H "Content-Type: application/json" \
-d '{
"firstname": "Max",
"lastname": "Mustermann",
"email": "max@example.com"
}'
Antwort:
{
"id": 1,
"firstname": "Max",
"lastname": "Mustermann",
"email": "max@example.com"
}
In der Console siehst du:
Hibernate: insert into persons (email, firstname, lastname)
values (?, ?, ?)
Das hat Hibernate automatisch generiert und ausgeführt!
2. Alle Personen abrufen (GET):
curl http://localhost:8080/api/persons
Antwort:
[
{
"id": 1,
"firstname": "Max",
"lastname": "Mustermann",
"email": "max@example.com"
}
]
In der Console:
Hibernate: select p1_0.id, p1_0.email, p1_0.firstname, p1_0.lastname
from persons p1_0
3. Person by ID abrufen (GET):
curl http://localhost:8080/api/persons/1
4. Person aktualisieren (PUT):
curl -X PUT http://localhost:8080/api/persons/1 \
-H "Content-Type: application/json" \
-d '{
"firstname": "Maximilian",
"lastname": "Mustermann",
"email": "maximilian@example.com"
}'
In der Console:
Hibernate: update persons
set email=?, firstname=?, lastname=?
where id=?
5. Person löschen (DELETE):
curl -X DELETE http://localhost:8080/api/persons/1
In der Console:
Hibernate: delete from persons where id=?
Zwischencheck – Verstanden?
Bevor du weitergehst:
- [ ] Deine App startet ohne Fehler
- [ ] Du siehst SQL-Statements in der Console
- [ ] POST /api/persons erstellt eine Person
- [ ] GET /api/persons gibt die Person zurück
- [ ] Du verstehst @Entity, @Id, @Column
Klappt nicht? Scrolle runter zur Troubleshooting-Sektion!
🎉 AHA-Moment #6: „Ich habe eine komplette REST API mit Datenbank-Persistierung gebaut – OHNE eine Zeile SQL zu schreiben!“
🟡 PROFESSIONALS – Production-Ready Setup
Glückwunsch! Die Grundlagen sitzen. Aber H2 ist nur zum Lernen – für echte Projekte brauchst du MariaDB!
Schritt 10: MariaDB Setup
Option 1: XAMPP (Windows/Mac)
Download: https://www.apachefriends.org/
- XAMPP installieren
- XAMPP Control Panel öffnen
- „MySQL“ starten (das ist MariaDB!)
- „Shell“ öffnen
Datenbank erstellen:
mysql -u root -p # Passwort eingeben (meistens leer bei XAMPP) CREATE DATABASE persondb; SHOW DATABASES; EXIT;
Option 2: Docker (alle Plattformen)
docker run -d \ --name mariadb-dev \ -p 3306:3306 \ -e MYSQL_ROOT_PASSWORD=secret \ -e MYSQL_DATABASE=persondb \ mariadb:latest
Testen:
docker exec -it mariadb-dev mysql -u root -p # Passwort: secret SHOW DATABASES; EXIT;
Option 3: Lokale Installation (Linux)
# Ubuntu/Debian sudo apt-get update sudo apt-get install mariadb-server # Start sudo systemctl start mariadb # Datenbank erstellen sudo mysql CREATE DATABASE persondb; EXIT;
Schritt 11: MariaDB Profile konfigurieren
Erstelle: src/main/resources/application-mysql.properties
# MariaDB Configuration spring.datasource.url=jdbc:mariadb://localhost:3306/persondb spring.datasource.driver-class-name=org.mariadb.jdbc.Driver spring.datasource.username=root spring.datasource.password= # JPA / Hibernate Configuration spring.jpa.hibernate.ddl-auto=update spring.jpa.show-sql=true spring.jpa.properties.hibernate.format_sql=true spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MariaDBDialect # Logging logging.level.org.hibernate.SQL=DEBUG logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
Wichtige Änderungen:
ddl-auto=update statt create-drop
update= Tabellen bleiben erhalten, werden nur angepasstcreate-dropwürde Tabellen bei jedem Start löschen!
Wichtig: In Production nutzt du ddl-auto=none oder ddl-auto=validate und verwaltest Schema-Änderungen mit Flyway/Liquibase!
Schritt 12: Auf MariaDB umstellen
Ändere in application.properties:
# Active Profile spring.profiles.active=mysql
Starte die App neu:
mvn spring-boot:run
Schaue in die Console:
Hibernate: create table if not exists persons (
id bigint not null auto_increment,
email varchar(150),
firstname varchar(100) not null,
lastname varchar(100) not null,
primary key (id)
)
Teste die API – sie funktioniert genau wie vorher!
Schritt 13: Datenbank direkt ansehen
Mit XAMPP:
- Browser öffnen: http://localhost/phpmyadmin
- Datenbank „persondb“ auswählen
- Tabelle „persons“ anklicken
- Du siehst alle gespeicherten Personen!
Mit MariaDB CLI:
mysql -u root -p persondb SELECT * FROM persons;
Mit Docker:
docker exec -it mariadb-dev mysql -u root -psecret persondb SELECT * FROM persons;
Jetzt das Spannende:
- Erstelle eine Person über die API (POST)
- Schaue in die Datenbank – sie ist da!
- Stoppe die App (
Ctrl+C) - Starte die App neu
- Rufe GET /api/persons auf – die Person ist immer noch da!
🎉 AHA-Moment #7: „Die Daten bleiben erhalten! Das ist echte Persistierung, nicht nur In-Memory!“
Schritt 14: @Transactional verstehen
Was macht @Transactional?
Eine Transaktion ist wie ein „Alles-oder-Nichts“-Prinzip:
- Entweder alle Änderungen werden gespeichert (COMMIT)
- Oder KEINE Änderung wird gespeichert (ROLLBACK)
Beispiel ohne @Transactional:
public void transferMoney(Long from, Long to, double amount) {
Account source = accountRepository.findById(from);
source.withdraw(amount); // Geld abbuchen
accountRepository.save(source);
// CRASH! Server stürzt ab!
Account target = accountRepository.findById(to);
target.deposit(amount); // Geld einzahlen
accountRepository.save(target);
}
Problem: Geld wurde abgebucht, aber nicht eingezahlt! Geld verschwunden!
Mit @Transactional:
@Transactional
public void transferMoney(Long from, Long to, double amount) {
Account source = accountRepository.findById(from);
source.withdraw(amount);
accountRepository.save(source);
// CRASH! Server stürzt ab!
Account target = accountRepository.findById(to);
target.deposit(amount);
accountRepository.save(target);
}
Lösung: Bei Crash macht Spring ROLLBACK – beide Accounts bleiben unverändert!
Spring macht automatisch:
BEGIN; -- Start Transaktion UPDATE account; -- Abbuchung -- CRASH! ROLLBACK; -- Rückgängig machen
🎉 AHA-Moment #8: „@Transactional schützt meine Daten vor inkonsistenten Zuständen!“
Schritt 15: Connection Pooling mit HikariCP
Was ist ein Connection Pool?
Ohne Pool:
Request 1 → Neue DB-Verbindung aufbauen (langsam!) → Query → Verbindung schließen Request 2 → Neue DB-Verbindung aufbauen (langsam!) → Query → Verbindung schließen Request 3 → Neue DB-Verbindung aufbauen (langsam!) → Query → Verbindung schließen
Mit Pool:
Beim Start: 10 Verbindungen erstellen und bereithalten Request 1 → Verbindung aus Pool holen (schnell!) → Query → Zurück in Pool Request 2 → Verbindung aus Pool holen (schnell!) → Query → Zurück in Pool Request 3 → Verbindung aus Pool holen (schnell!) → Query → Zurück in Pool
Spring Boot nutzt automatisch HikariCP – den schnellsten Connection Pool für Java!
Konfiguration (optional):
# HikariCP Configuration spring.datasource.hikari.maximum-pool-size=10 spring.datasource.hikari.minimum-idle=5 spring.datasource.hikari.connection-timeout=30000 spring.datasource.hikari.idle-timeout=600000
Du musst nichts tun – HikariCP läuft automatisch!
🎉 AHA-Moment #9: „Spring Boot optimiert die Datenbank-Performance automatisch durch Connection Pooling!“
🔵 BONUS – Relationships (Optional!)
Du hast die Grundlagen und Production-Setup gemeistert! Dieser Bonus-Teil bereitet dich auf Tag 3 vor.
Schritt 16: OneToOne Relationship mit Address
Erweitern wir unser Modell: Jede Person hat EINE Adresse (OneToOne).
Erstelle: src/main/java/com/example/demo/model/Address.java
package com.example.demo.model;
import jakarta.persistence.*;
@Entity
@Table(name = "addresses")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String street;
@Column(nullable = false)
private String city;
@Column(nullable = false, length = 10)
private String zipCode;
@Column(nullable = false)
private String country;
// Konstruktoren
public Address() {}
public Address(String street, String city, String zipCode, String country) {
this.street = street;
this.city = city;
this.zipCode = zipCode;
this.country = country;
}
// Getter und Setter
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getZipCode() {
return zipCode;
}
public void setZipCode(String zipCode) {
this.zipCode = zipCode;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
}
Erweitere die Person-Entity:
@Entity
@Table(name = "persons")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// ... andere Felder wie vorher ...
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "address_id")
private Address address;
// Getter und Setter für address
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
}
Was bedeutet das?
@OneToOne
- Eine Person hat EINE Adresse
- Eine Adresse gehört zu EINER Person
cascade = CascadeType.ALL
- Wenn ich die Person speichere → Adresse wird automatisch mitgespeichert
- Wenn ich die Person lösche → Adresse wird automatisch mitgelöscht
orphanRemoval = true
- Wenn ich die Adresse von der Person entferne → Adresse wird aus DB gelöscht
- „Orphan“ = „Waise“ – eine Adresse ohne Person
@JoinColumn(name = „address_id“)
- Erstellt eine Foreign Key Spalte „address_id“ in der persons-Tabelle
- Verbindet Person mit Address
Teste es:
curl -X POST http://localhost:8080/api/persons \
-H "Content-Type: application/json" \
-d '{
"firstname": "Anna",
"lastname": "Schmidt",
"email": "anna@example.com",
"address": {
"street": "Hauptstraße 123",
"city": "Berlin",
"zipCode": "10115",
"country": "Deutschland"
}
}'
In der Console siehst du:
Hibernate: insert into addresses (city, country, street, zip_code)
values (?, ?, ?, ?)
Hibernate: insert into persons (address_id, email, firstname, lastname)
values (?, ?, ?, ?)
Zwei INSERTs! Erst Address, dann Person mit der address_id!
🎉 AHA-Moment #10: „Spring Boot hat automatisch ZWEI Tabellen erstellt und sie mit einem Foreign Key verbunden! Ich musste kein SQL für die Relationship schreiben!“
✅ Checkpoint: Hast du Tag 2 geschafft?
Grundlagen (🟢 – PFLICHT):
- [ ] Spring Boot Projekt startet ohne Fehler
- [ ] Du siehst SQL-Statements in der Console
- [ ] GET /api/persons funktioniert und gibt JSON zurück
- [ ] POST /api/persons erstellt eine neue Person
- [ ] PUT /api/persons/{id} updated eine Person
- [ ] DELETE /api/persons/{id} löscht eine Person
- [ ] Du verstehst @Entity, @Id, @GeneratedValue, @Column
- [ ] Du verstehst das Zusammenspiel Controller → Service → Repository
Professionals (🟡 – EMPFOHLEN):
- [ ] MariaDB läuft und ist verbunden
- [ ] Nach App-Neustart sind die Daten noch da
- [ ] Du kannst die Datenbank mit CLI/phpMyAdmin öffnen
- [ ] Validation funktioniert (leerer Vorname gibt 400 zurück)
- [ ] Du verstehst @Transactional und warum es wichtig ist
- [ ] Du verstehst Connection Pooling mit HikariCP
Bonus (🔵 – OPTIONAL):
- [ ] Du hast OneToOne Relationship implementiert
- [ ] Du verstehst cascade = CascadeType.ALL
- [ ] Du verstehst orphanRemoval = true
- [ ] Person mit Address funktioniert in der API
✅ Alle Grundlagen-Häkchen gesetzt?
Glückwunsch! Du bist bereit für Tag 3! 🎉
❌ Nicht alles funktioniert?
Kein Problem! Dein Rettungsplan:
- Prüfe ob MariaDB läuft (XAMPP Control Panel oder
docker ps) - Kontrolliere application-mysql.properties (Username, Passwort, URL)
- Schaue in die Logs – Hibernate zeigt genau was schief geht
- Lade das komplette Projekt unten herunter und vergleiche
Brauchst du mehr Zeit?
Nimm sie dir! Besser ein Tag länger und es richtig verstanden!
💬 Real Talk – Aus dem Java Fleet Büro
Nach der Session kam das Team zusammen…
Nova (aufgeregt): „Elyndra, das ist ja unglaublich! Ich habe jahrelang mit ArrayLists gekämpft und jetzt… Hibernate macht einfach alles automatisch!“
Elyndra lächelt „Ich weiß noch genau, wie das für mich war. Als ich bei AutoTech angefangen habe, hatten wir ein Legacy-System mit handgeschriebenem JDBC-Code. Tausende Zeilen SQL, PreparedStatements überall, Connection-Leaks… Ein Alptraum. Als wir dann auf JPA migriert sind, hat sich die Codebasis halbiert.“
Franz-Martin: „Ein Hoch auf die Abstraktionsebenen! In den 80ern haben wir noch direkt mit ISAM-Files gearbeitet. Dann kamen relationale Datenbanken – Revolution! Dann JDBC – viel einfacher! Dann Hibernate/JPA – noch eine Ebene höher! Jede Abstraktionsebene macht uns produktiver.“
Nova: „Aber ich verstehe noch nicht so ganz… Wie weiß Hibernate, welches SQL es generieren soll?“
Elyndra: „Gute Frage! Hibernate analysiert deine Entity-Klassen beim Start. Es schaut sich alle @Column, @Id, @GeneratedValue Annotations an und baut ein internes Metamodell. Wenn du dann save() aufrufst, schaut Hibernate: ‚Okay, Person-Entity, hat ID null, also INSERT. Welche Spalten? Schau ins Metamodell. Welche Werte? Hole sie aus dem Objekt via Reflection.‘ Und schon wird das SQL generiert!“
Franz-Martin: „Das ist übrigens nicht nur Convenience – es ist auch eine fundamentale Entkopplung! Dein Java-Code kennt keine SQL-Dialekte. Hibernate kennt sie. Du könntest von MariaDB zu PostgreSQL zu Oracle wechseln, und dein Code bleibt gleich. Nur der Dialect in der Configuration ändert sich. Das ist Portabilität auf höchster Ebene!“
Nova: „Okay, eine Sache verstehe ich noch nicht ganz – warum drei Schichten? Controller, Service, Repository?“
Elyndra: „Sehr gute Frage! Lass mich das mit einem Restaurant-Beispiel erklären:“
- Controller = Kellner: Nimmt Bestellungen entgegen (HTTP Requests), gibt Essen aus (HTTP Responses). Macht keine Koch-Arbeit!
- Service = Koch: Bereitet das Essen zu (Business-Logik). Entscheidet WAS gekocht wird und WIE.
- Repository = Vorratskammer: Holt Zutaten (Daten aus DB). Weiß wo welche Zutat liegt.
„Würdest du wollen dass der Kellner selbst in die Vorratskammer geht und kocht? Nein! Jede Rolle hat eine klare Verantwortung. Genauso im Code!“
Nova lacht „Das macht total Sinn! Also Controller ist dünn, Service hat die Logik, Repository holt die Daten.“
Franz-Martin: „Exakt! Das ist das Separation of Concerns Prinzip. Eine der wichtigsten Lektionen in Software Engineering. Wenn du das verstehst, verstehst du Clean Architecture!“
🐛 Troubleshooting – Häufige Probleme
Problem 1: App startet nicht – Datenbank-Verbindung fehlgeschlagen
Symptom:
Error creating bean with name 'dataSource' Cannot load driver class: org.mariadb.jdbc.Driver
Lösung:
- Prüfe
pom.xml– ist die MariaDB-Dependency drin? - Maven reload durchführen
- Prüfe ob MariaDB läuft (
docker psoder XAMPP Control Panel)
Problem 2: Tabelle existiert nicht
Symptom:
Table 'persondb.persons' doesn't exist
Lösung:
- Prüfe
ddl-autoin properties – solltecreate-drop(H2) oderupdate(MariaDB) sein - Schaue in Logs ob „create table“ Statement kam
- Verbinde zur DB und prüfe:
SHOW TABLES;
Problem 3: Validation funktioniert nicht
Symptom: POST mit leerem firstname gibt 200 OK statt 400 Bad Request
Lösung:
- Ist
@Validim Controller beim@RequestBody? - Ist die
spring-boot-starter-validationDependency drin? - Sind die Validierungs-Annotations (@NotBlank, @Email) auf den Feldern?
Problem 4: Daten verschwinden nach Neustart
Symptom: Mit MariaDB – nach Neustart sind Daten weg
Lösung:
- Prüfe
ddl-auto– sollteupdatesein, NICHTcreate-drop - Bei H2 ist das normal – es ist In-Memory!
Problem 5: „Person not found“ obwohl sie existiert
Symptom: GET /api/persons/1 gibt 404
Lösung:
- Prüfe in der Datenbank:
SELECT * FROM persons; - Prüfe die ID – vielleicht ist es nicht 1 sondern 2?
- Bei H2: Daten sind weg nach Neustart!
❓ FAQ – Häufig gestellte Fragen
F: Warum MariaDB und nicht H2 in-memory?
A: H2 ist super für schnelle Prototypen und Tests, aber für Lernen ist eine echte Datenbank besser. Du siehst wie Persistierung wirklich funktioniert, kannst die Datenbank direkt ansehen, und lernst Production-nahe Skills.
F: Was ist der Unterschied zwischen JPA und Hibernate?
A: JPA (Jakarta Persistence API) ist die Spezifikation – also das Interface. Hibernate ist eine Implementierung dieser Spezifikation. Andere Implementierungen sind EclipseLink oder OpenJPA. Spring Boot nutzt standardmäßig Hibernate.
F: Sollte ich ddl-auto=update in Production nutzen?
A: NIEMALS! In Production nutzt du ddl-auto=none oder ddl-auto=validate und verwaltest Schema-Änderungen mit Migrations-Tools wie Flyway oder Liquibase. update kann in Production gefährlich sein – es kann Daten löschen!
F: Was macht @Transactional wirklich?
A: Es startet eine Datenbank-Transaktion beim Methoden-Eintritt (BEGIN) und committed sie beim erfolgreichen Ende (COMMIT) oder rollt zurück bei Exception (ROLLBACK). Das stellt sicher, dass entweder ALLE Änderungen gespeichert werden oder KEINE.
F: Brauche ich wirklich einen Service-Layer?
A: Technisch nein, aber es ist Best Practice. Der Service ist da für Business-Logik, Transaktionen und Wiederverwendbarkeit. Controller sollen dünn sein – nur Request/Response Handling. Das macht den Code wartbar und testbar!
F: Warum braucht JPA einen Default-Konstruktor?
A: Hibernate nutzt Reflection um Objekte zu erstellen. Wenn es Daten aus der Datenbank lädt, erstellt es zuerst ein leeres Objekt (via Default-Konstruktor) und füllt dann die Felder. Ohne Default-Konstruktor gibt’s eine Exception!
F: Was ist der Unterschied zwischen save() und saveAndFlush()?
A: save() speichert in den Hibernate-Cache (noch nicht in DB). saveAndFlush() schreibt sofort in die Datenbank. Meistens brauchst du nur save() – Hibernate schreibt automatisch beim Transaction-Commit.
F: Was macht ihr bei persönlichen Problemen zwischen den Projekten?
A: Das ist… kompliziert. Manche Geschichten gehören nicht in Tech-Blogs, sondern in private logs. Aber das ist ein anderes Kapitel. Wenn du neugierig bist… die Suche oben auf java-developer.online kennt mehr als nur Tech-Artikel. 🔒
Spring Boot Aufbau - Tag 2
Spring Data JPA Basics
🗺️ Deine nächsten Schritte
✅ Du hast Tag 2 geschafft! Was jetzt?
Nächster Tag:
- 📜 Tag 3: JPA Relationships & Queries
- 📅 Veröffentlicht: Morgen
- 🎯 Thema: OneToMany, ManyToOne, Custom Queries, JPQL
Was du morgen lernst:
- OneToMany Relationship (Person hat viele Adressen)
- ManyToOne Relationship (Adresse gehört zu einer Person)
- Bidirectional vs Unidirectional Relationships
- Cascade Types (PERSIST, MERGE, REMOVE, ALL)
- Fetch Types (LAZY vs EAGER)
- Query Methods (findByLastname, findByEmailContaining)
- Custom Queries mit @Query und JPQL
- N+1 Query Problem verstehen und lösen
Vorbereitung für Tag 3:
- [ ] Tag 2 Checkpoint vollständig ✅
- [ ] MariaDB läuft stabil
- [ ] Du verstehst @Entity und @Id
- [ ] Du verstehst JpaRepository
Noch nicht bereit?
Kein Problem! Arbeite heute nochmal nach. Qualität vor Tempo! 💪
📥 Downloads & Ressourcen
Für diesen Tag:
📦 [Finales Projekt] – person-management-final.zip (Lösung zum Vergleichen)
Weiterführende Ressourcen:
Du hast 20% des Kurses geschafft! 💪
Alle Blogbeiträge dieser Serie:
👉 Spring Boot Aufbau – Komplette Übersicht
Das war Tag 2 vom Spring Boot Aufbau-Kurs!
Du kannst jetzt:
- ✅ Den Unterschied zwischen In-Memory und Database-Persistierung erklären
- ✅ H2 und MariaDB mit Spring Boot verbinden
- ✅ JPA Entities mit @Entity, @Id, @GeneratedValue, @Column erstellen
- ✅ JpaRepository-Interfaces nutzen ohne SQL zu schreiben
- ✅ Einen Service-Layer nach Best Practice bauen
- ✅ Einen vollständigen REST Controller mit CRUD-Operationen erstellen
- ✅ @Transactional nutzen und verstehen
- ✅ Die Datenbank direkt ansehen und verstehen was Hibernate macht
- ✅ Das 3-Schichten-Modell (Controller → Service → Repository) anwenden
- ✅ OneToOne Relationships mit Cascade implementieren (Bonus)
Morgen tauchen wir tiefer ein: Komplexe Relationships, Query Methods und Custom Queries! 🚀
Keep coding, keep learning! 💙
Tag 3 erscheint morgen. Bis dahin: Happy Coding!
P.S.: Manchmal verstecken sich die spannendsten Geschichten nicht im Code, sondern in den… nun ja, private logs. Die Suche oben auf java-developer.online weiß mehr! 😉
📚 Das könnte dich auch interessieren
Tags: #SpringBoot #SpringDataJPA #Hibernate #MariaDB #Database #Persistierung #CRUD #REST #Tutorial #Tag2
