
Von Dr. Cassian Holt, Senior Architect bei Java Fleet Systems Consulting
Schwierigkeit: 🟢 Einsteiger
Lesezeit: 25 Minuten
Hands-on Zeit: 30 Minuten
Voraussetzungen: Java Grundkenntnisse, keine KI-Erfahrung nötig
📚 Serie: Lokale KI mit llama.cpp
| Teil | Thema | Status |
|---|---|---|
| → 1 | Dein erstes lokales LLM | Du bist hier |
| 2 | Streaming — Token für Token | Verfügbar |
| 3 | Der Kaufberater-Chatbot | Demnächst |
| 4 | GPU-Power — CUDA, Metal, Vulkan | Demnächst |
| 5 | Halluzinationen bekämpfen | Demnächst |
| 6+ | RAG mit pgvector | Bei Interesse |
⚡ Das Wichtigste in 30 Sekunden
Dein Problem: Du willst KI in deine Java-App einbauen, aber Cloud-APIs kosten Geld und deine Daten verlassen den Rechner.
Die Lösung: Ein lokales LLM mit llama.cpp — läuft auf deinem Rechner, keine API-Keys, keine Cloud.
Klassische Anwendungsfälle:
- 🛒 Verkaufsberater-Chatbot: Produktempfehlungen ohne dass Kundendaten zu OpenAI wandern
- 💼 HR-Tool: Bewerbungen vorfiltern — sensible Personaldaten verlassen nie den Server
Heute lernst du:
- ✅ Was llama.cpp ist und warum es existiert
- ✅ Wie du ein LLM auf deinem Rechner startest
- ✅ Deinen ersten Prompt per Java abzusetzen
- ✅ Warum kleine Modelle Grenzen haben (Spoiler: Deutsch ist schwierig)
Für wen ist dieser Artikel?
- 🌱 Anfänger: Du hast noch nie ein LLM selbst betrieben — perfekt, wir starten bei Null
- 🌿 Erfahrene: Du kennst ChatGPT, willst aber lokal arbeiten
- 🌳 Profis: Spring Boot Integration kommt in Teil 2-3
Zeit-Investment: 30 Minuten bis zur ersten Antwort
👋 Cassian: „Lass uns ein LLM zum Laufen bringen“
Moin! 👋
Cassian hier. Heute bringen wir ein Sprachmodell auf deinem Rechner zum Laufen. Kein Cloud-Abo, keine API-Keys, keine Datenübertragung ins Internet.
Warum ist das relevant? Denk mal drüber nach:
- Eine Anwaltskanzlei muss 800 Seiten Vertragsunterlagen durcharbeiten — die können das nicht durch ChatGPT jagen, das wäre ein Mandatsgeheimnis-Desaster
- Ein Krankenhaus will Arztbriefe zusammenfassen — Patientendaten in der Cloud? Vergiss es
- Ein Industriebetrieb braucht einen Assistenten für Maschinenhandbücher — aber das Werk hat kein Internet
- Ein Game-Studio will NPCs mit echten Dialogen — aber nicht pro Spieler-Interaktion zahlen. Denn bei Cloud-APIs zahlst du pro Token — das ist die Schattenwährung der KI-Branche. Jedes Wort, jeder Satzfetzen kostet. Bei Millionen Spielern läppert sich das.
All das geht mit lokalen LLMs. Heute legst du den Grundstein.
Fair warning: Das erste Modell wird klein sein. 1,5 Milliarden Parameter. Es wird antworten — aber vielleicht nicht so, wie du erwartest. Das ist Teil der Lektion.
Sarah würde sagen: „Weniger reden, mehr machen.“ Also los.
🖼️ Das Konzept auf einen Blick
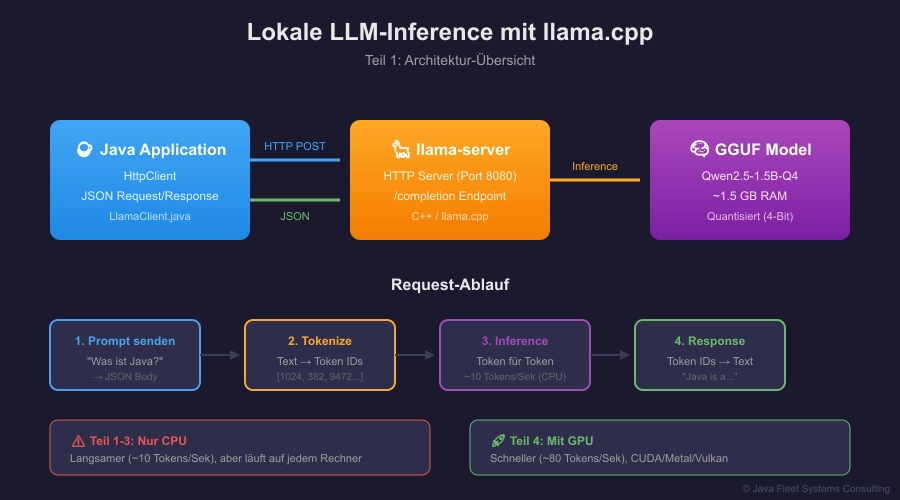
Abbildung 1: So funktioniert lokale LLM-Inference mit llama.cpp
🟢 GRUNDLAGEN
Was ist llama.cpp?
llama.cpp ist ein Open-Source-Projekt, das Large Language Models auf normaler Hardware zum Laufen bringt — ohne Python, ohne PyTorch, ohne CUDA-Zwang.
In 3 Sätzen:
- Geschrieben in C/C++ für maximale Performance
- Läuft auf CPU (GPU optional, kommt in Teil 4)
- Unterstützt quantisierte Modelle (4-Bit statt 16-Bit = weniger RAM)
💡 Neu hier? Was ist Quantisierung?
Normalerweise speichern LLMs ihre Gewichte in 16-Bit Zahlen. Quantisierung komprimiert das auf 4-Bit — das Modell wird ~4x kleiner, bei minimalem Qualitätsverlust.
Beispiel: Ein 7B-Modell braucht ~14 GB RAM in 16-Bit, aber nur ~4 GB in 4-Bit.
Warum lokal statt Cloud?
| Kriterium | Cloud (OpenAI & Co.) | Lokal (llama.cpp) |
|---|---|---|
| Kosten | Pro Token/Request | Einmalig (Hardware) |
| Datenschutz | Daten verlassen Rechner | Alles bleibt lokal |
| Latenz | Netzwerk-abhängig | Nur Hardware |
| Offline | ❌ Nein | ✅ Ja |
| Modellwahl | Was der Anbieter hat | Was du willst |
| DSGVO | Kompliziert | Einfach |
Wann macht lokal Sinn?
- Sensible Daten (Medizin, Finanzen, HR)
- Offline-Szenarien (Embedded, Air-Gapped)
- Experimente ohne Kostenrisiko
- DSGVO-Compliance ohne Auftragsverarbeitung
Der llama-server
llama.cpp kommt mit einem eingebauten HTTP-Server: llama-server.
Das ist unser Einstieg — wir müssen kein C++ schreiben, sondern sprechen einfach HTTP.
┌─────────────┐ HTTP ┌──────────────┐ │ Dein Java │ ───────────→ │ llama-server │ │ Code │ ←─────────── │ (LLM) │ └─────────────┘ JSON └──────────────┘
🟡 PROFESSIONALS
Installation: Schritt für Schritt
Schritt 1: llama.cpp herunterladen
Option A: Pre-built Binaries (empfohlen für den Start)
Geh zu: https://github.com/ggerganov/llama.cpp/releases
Download für dein OS:
- Windows:
llama-*-bin-win-*.zip - macOS:
llama-*-bin-macos-*.zip - Linux:
llama-*-bin-ubuntu-*.zip
Entpacken, fertig.
Option B: Selbst kompilieren (kommt in Teil 4)
Für GPU-Support kompilierst du später selbst — heute starten wir mit CPU.
Schritt 2: Ein Modell herunterladen
Wir brauchen ein GGUF-Modell. Meine Empfehlung für den Start:
Qwen2.5-1.5B-Instruct-Q4_K_M.gguf
- Größe: ~1 GB
- RAM-Bedarf: ~2 GB
- Deutsch: Wackelig — lässt sich durch Prompting teilweise geradebiegen, aber das Modell ist auf Englisch optimiert
Download von Hugging Face:
https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct-GGUF
Suche nach qwen2.5-1.5b-instruct-q4_k_m.gguf und lade es herunter.
💡 Warum Q4_K_M?
Das „Q4“ bedeutet 4-Bit Quantisierung. „K_M“ ist eine spezielle Variante mit gutem Qualität/Größe-Verhältnis.
Andere Optionen: Q8 (größer, besser) oder Q2 (kleiner, schlechter).
Schritt 3: Server starten
Öffne ein Terminal im llama.cpp-Ordner:
# Windows llama-server.exe -m pfad/zu/qwen2.5-1.5b-instruct-q4_k_m.gguf # Linux/macOS ./llama-server -m pfad/zu/qwen2.5-1.5b-instruct-q4_k_m.gguf
Erwartete Ausgabe:
llama_model_load: loading model from 'qwen2.5-1.5b-instruct-q4_k_m.gguf' ... server listening at http://127.0.0.1:8080
✅ Läuft! Der Server wartet jetzt auf Anfragen.
Schritt 4: Health-Check
Teste im Browser oder mit curl:
curl http://localhost:8080/health
Erwartete Antwort:
{"status":"ok"}
Dein erster Prompt
Mit curl testen
curl http://localhost:8080/completion \
-H "Content-Type: application/json" \
-d '{
"prompt": "Was ist Java? Antworte in einem Satz:",
"n_predict": 100
}'
Mögliche Antwort:
{
"content": "Java is a high-level, object-oriented programming language...",
"stop": true
}
Warte — auf Englisch?
Ja. Willkommen bei kleinen Modellen. Das 1,5B-Modell wurde hauptsächlich auf englischen Texten trainiert. Deutsch ist… ein Kampf.
Das Sprach-Experiment
Lass uns verschiedene Prompts testen:
# Versuch 1: Deutscher Prompt
curl http://localhost:8080/completion \
-d '{"prompt": "Was ist Java?", "n_predict": 100}'
# → Oft Englisch oder Denglisch 😅
# Versuch 2: Mit Deutsch-Anweisung
curl http://localhost:8080/completion \
-d '{"prompt": "Antworte auf Deutsch: Was ist Java?", "n_predict": 100}'
# → Besser, aber nicht zuverlässig
# Versuch 3: Englischer Prompt, deutsche Antwort erzwingen
curl http://localhost:8080/completion \
-d '{"prompt": "Answer in German only: What is Java?", "n_predict": 100}'
# → Manchmal besser! Warum? → Teil 3
Das ist kein Bug — das ist eine Lektion:
- Kleine Modelle haben kleine Sprachkompetenz
- Prompting macht einen Unterschied
- Manchmal ist ein größeres Modell die Antwort (Teil 4)

💡 Kurz innehalten: Prompting als Kernkompetenz
Was du gerade erlebt hast, ist mehr als ein technisches Problem. Es ist eine Schlüssellektion für deine Karriere.
Die unbequeme Wahrheit: KI-Modelle sind nur so gut wie die Prompts, die du ihnen gibst. Das gilt für ChatGPT, für lokale LLMs, für alles. Wer nicht prompten kann, bekommt mittelmäßige Ergebnisse — egal wie teuer das Modell ist.
Warum das für den Arbeitsmarkt relevant ist:
Unternehmen suchen nicht mehr nur „Entwickler“. Sie suchen Leute, die:
- Wissen, wie man KI-Modelle effektiv ansteuert
- Verstehen, warum ein Prompt funktioniert und ein anderer nicht
- Aus einem 1,5B-Modell rausholen können, wofür andere ein 70B-Modell brauchen
Das ist keine Zukunftsmusik — das ist jetzt. Prompt Engineering ist eine Skill, die dich von anderen unterscheidet. Nicht weil es fancy klingt, sondern weil es Ergebnisse liefert.
Was du gerade gelernt hast:
- Der gleiche Inhalt („Was ist Java?“) liefert je nach Formulierung völlig unterschiedliche Ergebnisse
- Ein englischer Prompt mit deutscher Antwort-Anweisung funktioniert oft besser als ein deutscher Prompt
- Das Modell „denkt“ nicht — es reagiert auf Muster. Wer die Muster kennt, gewinnt.
Praxistipp: Wenn das kleine Modell störrisch ist
Kleine Modelle können verdammt stur sein. Du probierst zehn Prompt-Varianten, und keine funktioniert richtig. Das ist frustrierend — aber du bist nicht allein.
Hier kommt der Trick: Nutze die großen Cloud-LLMs als Prompt-Coaches.
Frag ChatGPT, Claude oder DeepSeek:
„Ich nutze ein kleines 1.5B-Modell lokal. Es antwortet auf Deutsch-Prompts oft auf Englisch. Wie formuliere ich meinen Prompt besser?“
Die großen Modelle haben genug „Erfahrung“ mit Prompting, um dir Varianten vorzuschlagen, auf die du selbst nicht gekommen wärst. Ironie der Geschichte: Du nutzt Cloud-KI, um deine lokale KI besser zu prompten. Aber hey — wenn’s funktioniert, funktioniert’s.
In Teil 3 gehen wir tiefer: System-Prompts, Kontext-Management, und wie du auch aus kleinen Modellen brauchbare Ergebnisse holst. Aber die Grundlektion ist jetzt schon klar: Prompting ist kein Nice-to-have. Es ist die Kernkompetenz im KI-Zeitalter.
Java-Integration
Jetzt wird’s interessant. Wir bauen einen einfachen Java-Client.
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>de.javafleet</groupId>
<artifactId>llama-cpp-teil1</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>llama.cpp Serie - Teil 1</name>
<description>Dein erstes lokales LLM</description>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Jackson für JSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.12.1</version>
</plugin>
</plugins>
</build>
</project>
LlamaClient.java
package de.javafleet.llama;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
/**
* Einfacher Client für llama-server.
* Teil 1 der llama.cpp Serie von Java Fleet.
*/
public class LlamaClient {
private final String serverUrl;
private final HttpClient httpClient;
private final ObjectMapper objectMapper;
public LlamaClient(String serverUrl) {
this.serverUrl = serverUrl;
this.httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
this.objectMapper = new ObjectMapper();
}
/**
* Sendet einen Prompt an den llama-server und wartet auf die Antwort.
*
* @param prompt Der Prompt-Text
* @param maxTokens Maximale Anzahl zu generierender Tokens
* @return Die generierte Antwort
*/
public String complete(String prompt, int maxTokens) throws Exception {
// Request-Body bauen
String requestBody = objectMapper.writeValueAsString(new CompletionRequest(
prompt,
maxTokens,
0.7, // temperature
false // stream (kommt in Teil 2!)
));
// HTTP-Request erstellen
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(serverUrl + "/completion"))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(requestBody))
.timeout(Duration.ofMinutes(2)) // LLMs brauchen Zeit!
.build();
// Request senden
HttpResponse<String> response = httpClient.send(
request,
HttpResponse.BodyHandlers.ofString()
);
// Response parsen
if (response.statusCode() != 200) {
throw new RuntimeException("Server returned: " + response.statusCode());
}
JsonNode json = objectMapper.readTree(response.body());
return json.get("content").asText();
}
/**
* Request-Objekt für die /completion API.
*/
record CompletionRequest(
String prompt,
int n_predict,
double temperature,
boolean stream
) {}
}
FirstLLMCall.java (Main-Klasse)
package de.javafleet.llama;
/**
* Dein erstes lokales LLM!
*
* Voraussetzung: llama-server läuft auf localhost:8080
*
* Start: ./llama-server -m qwen2.5-1.5b-instruct-q4_k_m.gguf
*/
public class FirstLLMCall {
public static void main(String[] args) {
System.out.println("🦙 Dein erstes lokales LLM");
System.out.println("=" .repeat(50));
LlamaClient client = new LlamaClient("http://localhost:8080");
// Verschiedene Prompts testen
String[] prompts = {
"Was ist Java?",
"Antworte auf Deutsch: Was ist Java?",
"Answer in German only: What is Java?"
};
for (int i = 0; i < prompts.length; i++) {
System.out.println("\n📝 Versuch " + (i + 1) + ": " + prompts[i]);
System.out.println("-".repeat(50));
try {
long start = System.currentTimeMillis();
String response = client.complete(prompts[i], 100);
long duration = System.currentTimeMillis() - start;
System.out.println("💬 Antwort:");
System.out.println(response);
System.out.println("\n⏱️ Dauer: " + duration + " ms");
} catch (Exception e) {
System.err.println("❌ Fehler: " + e.getMessage());
System.err.println(" Läuft der llama-server auf localhost:8080?");
}
}
System.out.println("\n" + "=".repeat(50));
System.out.println("✅ Das war's! Dein LLM hat geantwortet.");
System.out.println(" (War es auf Deutsch? Englisch? Beides? 😅)");
System.out.println("\n📖 Weiter geht's in Teil 2: Streaming!");
}
}
Ausführen
# 1. Projekt bauen mvn clean compile # 2. Ausführen mvn exec:java -Dexec.mainClass="de.javafleet.llama.FirstLLMCall"
Erwartete Ausgabe:
🦙 Dein erstes lokales LLM ================================================== 📝 Versuch 1: Was ist Java? -------------------------------------------------- 💬 Antwort: Java is a high-level, object-oriented programming language... ⏱️ Dauer: 3847 ms 📝 Versuch 2: Antworte auf Deutsch: Was ist Java? -------------------------------------------------- 💬 Antwort: Java ist eine objektorientierte Programmiersprache, die... ⏱️ Dauer: 4123 ms ...
🔵 BONUS
Für Neugierige: Was passiert unter der Haube?
Wenn du den Server startest, passiert folgendes:
- Modell laden: Die GGUF-Datei wird in den RAM geladen (~2 GB)
- Tokenizer initialisieren: Text → Zahlen Mapping
- HTTP-Server starten: Wartet auf Port 8080
Bei jedem Request:
- Tokenize: Dein Prompt wird in Tokens umgewandelt
- Inference: Das Modell generiert Token für Token
- Detokenize: Tokens werden zurück in Text umgewandelt
- Response: JSON wird zurückgeschickt
Warum ist das langsam auf CPU?
Ein 1,5B-Modell hat 1.500.000.000 Parameter. Bei jedem Token werden Matrix-Multiplikationen über diese Parameter durchgeführt. Auf CPU: ~8-15 Tokens/Sekunde. Auf GPU: ~60-100 Tokens/Sekunde.
→ GPU kommt in Teil 4!
Hardware-Empfehlungen
| Modell | RAM-Bedarf | Deutsch-Qualität | Für wen? |
|---|---|---|---|
| TinyLlama 1.1B Q4 | ~1 GB | ⭐ (meist Englisch) | Nur zum Testen |
| Qwen2.5-1.5B Q4 | ~1.5 GB | ⭐⭐ (Prompting hilft) | Empfehlung Teil 1-2 |
| Phi-3 Mini 3.8B Q4 | ~2.5 GB | ⭐⭐⭐ | Wenn CPU stark |
| Mistral 7B Q4 | ~4-5 GB | ⭐⭐⭐⭐ | Mit GPU (Teil 4) |
💡 Praxis-Tipps
Für Einsteiger 🌱
- Starte mit dem Qwen2.5-1.5B — klein genug für jeden Laptop
- Erwarte kein perfektes Deutsch — kleine Modelle sind auf Englisch optimiert, Prompting hilft aber (Teil 3)
- Timeout erhöhen — LLMs auf CPU brauchen Zeit (30+ Sekunden möglich)
Für den Alltag 🌿
- Server als Hintergrund-Prozess —
nohup ./llama-server -m model.gguf & - Health-Check einbauen — Prüfe
/healthbevor du Requests sendest - Logging aktivieren —
--log-disable falsefür Debugging
Für Profis 🌳
- Context Size beachten — Default ist oft 512, für längere Gespräche:
--ctx-size 2048 - Batch Size tunen —
--batch-size 512für schnellere Prompt-Verarbeitung - Mehrere Slots —
--parallel 2für gleichzeitige Requests
🛠️ Tools & Ressourcen
Downloads
| Was | Link |
|---|---|
| llama.cpp Releases | https://github.com/ggerganov/llama.cpp/releases |
| Qwen2.5 GGUF Modelle | https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct-GGUF |
| Projekt-Code (ZIP) | Download |
Weiterführend
| Ressource | Beschreibung |
|---|---|
| llama.cpp GitHub | Offizielle Dokumentation |
| Hugging Face | Modell-Downloads |
| GGUF Spec | Format-Dokumentation |
❓ FAQ — Häufige Fragen
Frage 1: Brauche ich eine GPU?
Antwort: Nein! Für Teil 1-3 reicht CPU völlig. GPU macht es schneller (Teil 4), ist aber nicht nötig zum Lernen.
Frage 2: Welches Modell für den Anfang?
Antwort: Qwen2.5-1.5B-Instruct-Q4_K_M. Klein genug für jeden Laptop, groß genug um zu funktionieren.
Frage 3: Ist das legal?
Antwort: Ja! Die meisten GGUF-Modelle haben offene Lizenzen (Apache 2.0, MIT, Llama License). Prüfe die Lizenz auf Hugging Face.
Frage 4: Wie gut sind kleine Modelle wirklich?
Antwort: Für einfache Aufgaben: überraschend gut. Für komplexe Aufgaben oder nicht-englische Sprachen: begrenzt. Das ist der Trade-off.
Frage 5: Warum antwortet das Modell auf Englisch?
Antwort: Kleine Modelle (1-3B) sind hauptsächlich auf englischen Texten trainiert. Deutsch funktioniert, aber nicht zuverlässig. Lösung: Besseres Prompting (Teil 3) oder größeres Modell (Teil 4).
Frage 6: llama.cpp vs. Ollama — was ist der Unterschied?
Antwort: Ollama ist ein Wrapper um llama.cpp mit einfacherem Setup. Wir nutzen llama.cpp direkt, um zu verstehen was passiert. Später kannst du Ollama nutzen wenn du willst.
Frage 7: Was macht ihr bei Java Fleet, wenn das Modell Quatsch antwortet?
Antwort: Das ist… frustrierend. Manchmal hilft Prompt-Engineering, manchmal ein größeres Modell, manchmal Akzeptanz. Manche Frustrationen gehören nicht in Tech-Blogs, sondern in private logs. 🔒
📚 Weiter in der Serie
| Teil | Thema | Link |
|---|---|---|
| ✅ 1 | Dein erstes lokales LLM | Du bist hier |
| → 2 | Streaming — Token für Token | Zum Artikel |
| 3 | Der Kaufberater-Chatbot | Demnächst |
| 4 | GPU-Power — CUDA, Metal, Vulkan | Demnächst |
| 5 | Halluzinationen bekämpfen | Demnächst |
| 6+ | RAG mit pgvector | Bei Interesse |
🎯 Zusammenfassung
Das hast du heute gelernt:
- ✅ llama.cpp installieren und starten
- ✅ Ein GGUF-Modell herunterladen
- ✅ Prompts per curl und Java senden
- ✅ Das Sprach-Problem bei kleinen Modellen verstehen
Das nimmst du mit:
- Lokale LLMs sind real und nutzbar
- Kleine Modelle haben Grenzen (Sprache!)
- Prompting macht einen Unterschied
- Hardware/Modellwahl ist nicht egal
💬 Dein Feedback zählt!
Dein erstes LLM läuft! Aber die Antworten kommen… langsam. Und in einem Rutsch.
Nächste Woche: Streaming — Token für Token, wie bei ChatGPT.
Wohin soll die Serie gehen?
Diese Serie wächst mit euch. Teil 1-5 sind geplant, aber Teil 6+ (RAG mit Vektordatenbank) kommt nur, wenn ihr es wollt.
Ich will wissen:
- War das zu schnell? Zu langsam? Genau richtig?
- Welchen Bot willst DU bauen?
- Wo bist du hängengeblieben?
👉 Schreib’s in die Kommentare! Jeder Kommentar hilft mir, die Serie besser zu machen.
📥 Downloads
- 📦 Maven-Projekt (ZIP) — Kompletter Code zum Loslegen
- 📄Qwen2.5-1.5B-Instruct-GGUF auf Hugging Face
Fragen? Schreib mir:
- Cassian: cassian.holt@java-developer.online
© 2025 Java Fleet Systems Consulting | java-developer.online
📚 Das könnte dich auch interessieren
Tags: #llama-cpp #Java #LLM #LokalKI #MachineLearning #Tutorial