
Von Dr. Cassian Holt, Senior Architect bei Java Fleet Systems Consulting
Schwierigkeit: 🟡 Mittel
Lesezeit: 30 Minuten
Hands-on Zeit: 45 Minuten
Voraussetzungen: Teil 1 abgeschlossen, Spring Boot Grundkenntnisse
📚 Serie: Lokale KI mit llama.cpp
| Teil | Thema | Status |
|---|---|---|
| 1 | Dein erstes lokales LLM | ✅ Verfügbar |
| → 2 | Streaming — Token für Token | Du bist hier |
| 3 | Der Kaufberater-Chatbot | Demnächst |
| 4 | GPU-Power — CUDA, Metal, Vulkan | Demnächst |
| 5 | Halluzinationen bekämpfen | Demnächst |
| 6+ | RAG mit pgvector | Bei Interesse |
Neu in der Serie? Starte mit Teil 1 für das grundlegende Setup.
⚡ Das Wichtigste in 30 Sekunden
Dein Problem: Dein LLM antwortet — aber du wartest 5 Sekunden auf einen Textblock. Das fühlt sich langsam an.
Die Lösung: Streaming! Token für Token, wie bei ChatGPT.
Klassische Anwendungsfälle:
- 💬 Support-Chatbot: Kunden sehen sofort, dass der Bot arbeitet — keine „Ist er abgestürzt?“-Momente
- 🛒 Produktberater: Kunden bleiben dran statt abzuspringen — die Antwort „entsteht“ vor ihren Augen
Heute lernst du:
- ✅ Warum Streaming die UX verbessert
- ✅ Server-Sent Events (SSE) von llama-server empfangen
- ✅ Ein Spring Boot Backend als Proxy bauen
- ✅ WebSockets zum Frontend implementieren
- ✅ Eine Web-UI mit live-tippender Antwort
Für wen ist dieser Artikel?
- 🌱 Anfänger: Du lernst SSE und WebSockets von Grund auf
- 🌿 Erfahrene: Du baust einen funktionierenden Streaming-Proxy
- 🌳 Profis: Im Bonus: Backpressure und Connection-Management
Zeit-Investment: 45 Minuten bis zur live-tippenden Antwort
👋 Cassian: „Lass uns den ChatGPT-Effekt nachbauen“
Moin! 👋
Kennst du das? Du fragst ChatGPT was, und die Antwort erscheint Buchstabe für Buchstabe. Das ist kein Gimmick — das ist Streaming. Und es macht einen riesigen Unterschied.
Warum? Stell dir vor:
- Ein Entwickler generiert Code — er sieht nach 2 Sekunden, dass der Ansatz falsch ist, und bricht ab. Ohne Streaming hätte er 10 Sekunden gewartet.
- Ein Student lässt sich ein Konzept erklären — er liest mit, versteht Schritt für Schritt. Nicht: Warten… warten… TEXTWALL.
- Ein Anwalt lässt Vertragsklauseln analysieren — er sieht die Argumentation entstehen, kann eingreifen wenn’s in die falsche Richtung geht.
Heute bauen wir das nach. Mit WebSockets, Spring Boot, und einem Frontend das live mitschreibt.
Ja, unser 1.5B-Modell antwortet vielleicht immer noch auf Englisch. Das Problem kennen wir aus Teil 1. Aber jetzt antwortet es wenigstens LIVE auf Englisch. Fortschritt! 😅
Ich könnte jetzt erklären, warum Server-Sent Events technisch eleganter sind als— okay, ich seh deinen Blick. Lass uns bauen.
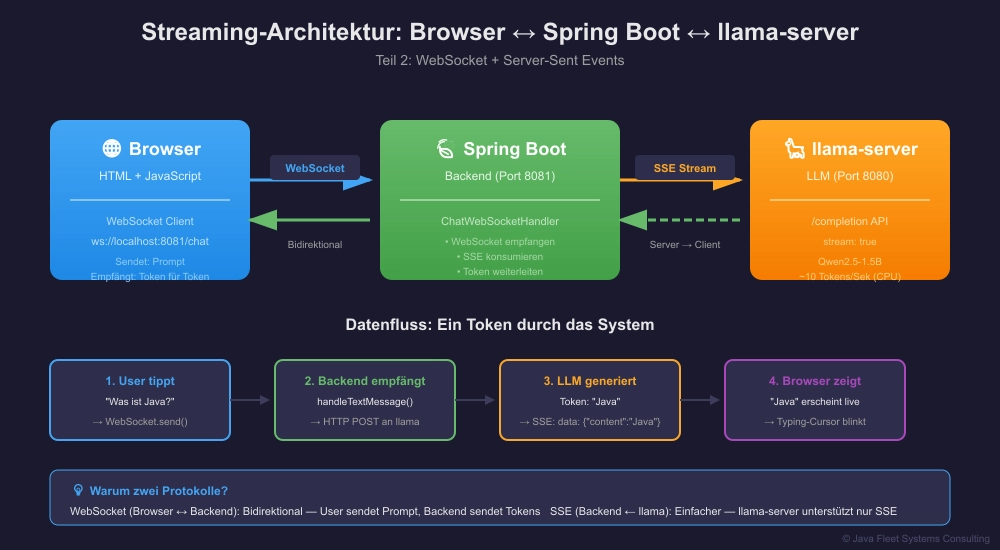
🖼️ Das Konzept auf einen Blick
Abbildung 1: Die komplette Streaming-Pipeline von llama-server bis Browser
🟢 GRUNDLAGEN
Warum Streaming?
Das Problem mit Blocking-Requests:

User fragt: "Was ist Java?" [====== 5 Sekunden Stille ======] *Plötzlich erscheint ein ganzer Textblock*
Das fühlt sich langsam an — obwohl das Modell die ganze Zeit arbeitet!
Mit Streaming:
User fragt: "Was ist Java?" J... a... v... a... i... s... t... e... i... n... e... (Tokens erscheinen während sie generiert werden)
Technisch: Was passiert bei Streaming?
LLMs generieren Text Token für Token. Ohne Streaming wartet der Server, bis alle Tokens da sind. Mit Streaming schickt er jeden Token sofort.
| Aspekt | Blocking | Streaming |
|---|---|---|
| Latenz bis erste Antwort | Hoch (komplette Generation) | Niedrig (erstes Token) |
| User Experience | „Ist es abgestürzt?“ | „Es arbeitet!“ |
| Technische Komplexität | Einfach | Mittel |
Server-Sent Events (SSE)
llama-server nutzt Server-Sent Events für Streaming. Das ist ein HTTP-Standard für unidirektionale Streams.
Client Server | | |---- HTTP GET ------>| | | |<--- data: token1 ---| |<--- data: token2 ---| |<--- data: token3 ---| |<--- data: [DONE] ---| | |
💡 Neu hier? Was sind Server-Sent Events?
SSE ist wie ein Radio: Du schaltest ein (HTTP-Request), und der Server sendet kontinuierlich Daten, bis er fertig ist oder du abschaltest.
Format:
data: {json}\n\n
🟡 PROFESSIONALS
Schritt 1: Streaming mit curl testen
Bevor wir Code schreiben, testen wir das Streaming:
curl http://localhost:8080/completion \
-H "Content-Type: application/json" \
-d '{
"prompt": "Was ist Java?",
"n_predict": 100,
"stream": true
}'
Erwartete Ausgabe:
data: {"content":"J","stop":false}
data: {"content":"ava","stop":false}
data: {"content":" ist","stop":false}
data: {"content":" eine","stop":false}
...
data: {"content":"","stop":true}
Du siehst: Jede Zeile ist ein Token! Das stream: true macht den Unterschied.
Schritt 2: Die Architektur verstehen
Warum brauchen wir ein Backend dazwischen?
┌─────────────┐ WebSocket ┌─────────────────┐ SSE ┌──────────────┐ │ Browser │ ←───────────────→ │ Spring Boot │ ←────────────→ │ llama-server │ │ (Frontend) │ │ (Backend) │ │ (1.5B, CPU) │ └─────────────┘ └─────────────────┘ └──────────────┘
Gründe für das Backend:
- CORS: Browser können nicht direkt mit llama-server sprechen
- Protokoll-Übersetzung: SSE → WebSocket
- Abstraktion: Frontend kennt llama-server nicht
- Später: Authentication, Rate-Limiting, Logging
Schritt 3: Spring Boot Projekt aufsetzen
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.2</version>
</parent>
<groupId>de.javafleet</groupId>
<artifactId>llama-cpp-teil2</artifactId>
<version>1.0.0</version>
<properties>
<java.version>21</java.version>
</properties>
<dependencies>
<!-- Spring WebFlux für reaktive Streams -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- WebSocket Support -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
<!-- Jackson für JSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>
</project>
Schritt 4: WebSocket-Konfiguration
package de.javafleet.llama.config;
import de.javafleet.llama.handler.ChatWebSocketHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.config.annotation.EnableWebSocket;
import org.springframework.web.socket.config.annotation.WebSocketConfigurer;
import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry;
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
private final ChatWebSocketHandler chatHandler;
public WebSocketConfig(ChatWebSocketHandler chatHandler) {
this.chatHandler = chatHandler;
}
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(chatHandler, "/chat")
.setAllowedOrigins("*"); // In Production einschränken!
}
}
Schritt 5: Der WebSocket Handler — Das Herzstück
package de.javafleet.llama.handler;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import org.springframework.web.socket.CloseStatus;
import org.springframework.web.socket.TextMessage;
import org.springframework.web.socket.WebSocketSession;
import org.springframework.web.socket.handler.TextWebSocketHandler;
import java.io.IOException;
import java.util.Map;
/**
* WebSocket Handler der SSE von llama-server empfängt
* und Token für Token ans Frontend weiterleitet.
*/
@Component
public class ChatWebSocketHandler extends TextWebSocketHandler {
private static final Logger log = LoggerFactory.getLogger(ChatWebSocketHandler.class);
private static final String LLAMA_SERVER = "http://localhost:8080";
private final WebClient webClient;
private final ObjectMapper objectMapper;
public ChatWebSocketHandler() {
this.webClient = WebClient.builder()
.baseUrl(LLAMA_SERVER)
.build();
this.objectMapper = new ObjectMapper();
}
@Override
public void afterConnectionEstablished(WebSocketSession session) {
log.info("WebSocket verbunden: {}", session.getId());
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) {
String userPrompt = message.getPayload();
log.info("Prompt empfangen: {}", userPrompt);
// SSE-Stream von llama-server starten
webClient.post()
.uri("/completion")
.header("Content-Type", "application/json")
.bodyValue(Map.of(
"prompt", userPrompt,
"stream", true,
"n_predict", 200
))
.retrieve()
.bodyToFlux(String.class)
.doOnNext(chunk -> processChunk(session, chunk))
.doOnComplete(() -> sendMessage(session, "[DONE]"))
.doOnError(e -> {
log.error("Stream-Fehler: {}", e.getMessage());
sendMessage(session, "[ERROR] " + e.getMessage());
})
.subscribe();
}
/**
* Verarbeitet einen SSE-Chunk und extrahiert den Token.
*/
private void processChunk(WebSocketSession session, String chunk) {
try {
// SSE-Format: "data: {json}"
if (chunk.startsWith("data: ")) {
String json = chunk.substring(6).trim();
if (!json.isEmpty() && !json.equals("[DONE]")) {
JsonNode node = objectMapper.readTree(json);
String content = node.path("content").asText("");
if (!content.isEmpty()) {
sendMessage(session, content);
}
}
}
} catch (Exception e) {
log.warn("Chunk-Parsing fehlgeschlagen: {}", chunk);
}
}
/**
* Sendet eine Nachricht an den WebSocket-Client.
*/
private void sendMessage(WebSocketSession session, String message) {
if (session.isOpen()) {
try {
session.sendMessage(new TextMessage(message));
} catch (IOException e) {
log.error("Senden fehlgeschlagen: {}", e.getMessage());
}
}
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) {
log.info("WebSocket geschlossen: {} - {}", session.getId(), status);
}
}
Schritt 6: Das Frontend — Live-tippende Antwort
<!DOCTYPE html>
<html lang="de">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>🦙 llama.cpp Streaming Demo</title>
<style>
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
font-family: 'Segoe UI', system-ui, sans-serif;
background: #1a1a2e;
color: #e8e8e8;
min-height: 100vh;
display: flex;
flex-direction: column;
align-items: center;
padding: 2rem;
}
.container {
max-width: 800px;
width: 100%;
}
header {
text-align: center;
margin-bottom: 2rem;
}
h1 {
font-size: 2rem;
margin-bottom: 0.5rem;
}
.subtitle {
color: #9e9e9e;
}
.chat-container {
background: #2d2d4a;
border-radius: 12px;
padding: 1.5rem;
margin-bottom: 1rem;
min-height: 300px;
}
.message {
margin-bottom: 1rem;
padding: 1rem;
border-radius: 8px;
}
.user-message {
background: #42A5F5;
margin-left: 20%;
}
.assistant-message {
background: #3d3d5c;
margin-right: 20%;
}
.typing-cursor {
display: inline-block;
width: 2px;
height: 1em;
background: #42A5F5;
animation: blink 0.7s infinite;
vertical-align: text-bottom;
}
@keyframes blink {
0%, 50% { opacity: 1; }
51%, 100% { opacity: 0; }
}
.input-container {
display: flex;
gap: 1rem;
}
input {
flex: 1;
padding: 1rem;
border: none;
border-radius: 8px;
background: #2d2d4a;
color: #e8e8e8;
font-size: 1rem;
}
input:focus {
outline: 2px solid #42A5F5;
}
button {
padding: 1rem 2rem;
border: none;
border-radius: 8px;
background: #42A5F5;
color: white;
font-size: 1rem;
cursor: pointer;
transition: background 0.2s;
}
button:hover {
background: #1E88E5;
}
button:disabled {
background: #666;
cursor: not-allowed;
}
.status {
text-align: center;
margin-top: 1rem;
font-size: 0.9rem;
color: #9e9e9e;
}
.status.connected { color: #66BB6A; }
.status.error { color: #EF5350; }
footer {
margin-top: 2rem;
text-align: center;
color: #666;
font-size: 0.8rem;
}
</style>
</head>
<body>
<div class="container">
<header>
<h1>🦙 llama.cpp Streaming</h1>
<p class="subtitle">Teil 2 der Serie — Token für Token wie bei ChatGPT</p>
</header>
<div class="chat-container" id="chat"></div>
<div class="input-container">
<input type="text" id="prompt" placeholder="Schreib deine Frage..."
onkeypress="if(event.key === 'Enter') sendMessage()">
<button onclick="sendMessage()" id="sendBtn">Senden</button>
</div>
<p class="status" id="status">Verbinde...</p>
<footer>
<p>Java Fleet Systems Consulting | java-developer.online</p>
</footer>
</div>
<script>
let ws = null;
let currentAssistantDiv = null;
// WebSocket verbinden
function connect() {
const wsUrl = `ws://${window.location.host}/chat`;
ws = new WebSocket(wsUrl);
ws.onopen = () => {
document.getElementById('status').textContent = '✅ Verbunden';
document.getElementById('status').className = 'status connected';
document.getElementById('sendBtn').disabled = false;
};
ws.onmessage = (event) => {
const data = event.data;
if (data === '[DONE]') {
// Streaming beendet
removeCursor();
document.getElementById('sendBtn').disabled = false;
} else if (data.startsWith('[ERROR]')) {
appendToAssistant(data);
removeCursor();
} else {
// Token empfangen
appendToAssistant(data);
}
};
ws.onclose = () => {
document.getElementById('status').textContent = '❌ Verbindung getrennt';
document.getElementById('status').className = 'status error';
document.getElementById('sendBtn').disabled = true;
// Reconnect nach 3 Sekunden
setTimeout(connect, 3000);
};
ws.onerror = (error) => {
console.error('WebSocket Error:', error);
};
}
// Nachricht senden
function sendMessage() {
const input = document.getElementById('prompt');
const message = input.value.trim();
if (!message || !ws || ws.readyState !== WebSocket.OPEN) return;
// User-Nachricht anzeigen
addMessage(message, 'user');
// Assistant-Div vorbereiten
currentAssistantDiv = addMessage('', 'assistant');
addCursor();
// Senden
ws.send(message);
input.value = '';
document.getElementById('sendBtn').disabled = true;
}
// Nachricht zum Chat hinzufügen
function addMessage(text, role) {
const chat = document.getElementById('chat');
const div = document.createElement('div');
div.className = `message ${role}-message`;
div.textContent = text;
chat.appendChild(div);
chat.scrollTop = chat.scrollHeight;
return div;
}
// Token zur aktuellen Antwort hinzufügen
function appendToAssistant(token) {
if (currentAssistantDiv) {
// Cursor entfernen, Text hinzufügen, Cursor wieder hinzufügen
removeCursor();
currentAssistantDiv.textContent += token;
addCursor();
// Auto-scroll
const chat = document.getElementById('chat');
chat.scrollTop = chat.scrollHeight;
}
}
// Blink-Cursor hinzufügen
function addCursor() {
if (currentAssistantDiv && !currentAssistantDiv.querySelector('.typing-cursor')) {
const cursor = document.createElement('span');
cursor.className = 'typing-cursor';
currentAssistantDiv.appendChild(cursor);
}
}
// Cursor entfernen
function removeCursor() {
if (currentAssistantDiv) {
const cursor = currentAssistantDiv.querySelector('.typing-cursor');
if (cursor) cursor.remove();
}
}
// Beim Laden verbinden
connect();
</script>
</body>
</html>
Schritt 7: Application Klasse und Start
package de.javafleet.llama;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class LlamaStreamingApplication {
public static void main(String[] args) {
SpringApplication.run(LlamaStreamingApplication.class, args);
}
}
application.properties:
server.port=8081 # llama-server läuft auf 8080, wir auf 8081
Schritt 8: Starten und Testen
# Terminal 1: llama-server ./llama-server -m qwen2.5-1.5b-instruct-q4_k_m.gguf # Terminal 2: Spring Boot mvn spring-boot:run # Browser öffnen http://localhost:8081
Das Ergebnis:
Die Antwort erscheint Token für Token — wie bei ChatGPT!
🔵 BONUS
Für Neugierige: Warum WebSockets statt SSE zum Browser?
| Aspekt | SSE (Server → Browser) | WebSocket |
|---|---|---|
| Richtung | Nur Server → Client | Bidirektional |
| Reconnect | Automatisch | Manuell |
| Komplexität | Einfacher | Mehr Code |
| Use-Case | Nur Streaming | Chat (senden + empfangen) |
Wir brauchen bidirektionale Kommunikation (User sendet Prompt, Server sendet Tokens), deshalb WebSocket.
Backpressure: Was wenn der Client zu langsam ist?
Bei WebFlux/Reactor wird Backpressure automatisch gehandelt. Wenn der Client langsamer ist als der Server, werden Tokens gepuffert.
// Explizites Rate-Limiting (optional): .doOnNext(chunk -> processChunk(session, chunk)) .delayElements(Duration.ofMillis(10)) // Künstliche Verzögerung
Connection-Management
// In Production: Sessions tracken
private final Map<String, WebSocketSession> sessions = new ConcurrentHashMap<>();
@Override
public void afterConnectionEstablished(WebSocketSession session) {
sessions.put(session.getId(), session);
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) {
sessions.remove(session.getId());
}
💡 Praxis-Tipps
Für Einsteiger 🌱
- Teste erst mit curl — Stelle sicher, dass SSE funktioniert, bevor du das Backend baust
- Browser DevTools nutzen — Network-Tab zeigt WebSocket-Frames
- Fehler im Terminal prüfen — Spring Boot loggt alle Fehler
Für den Alltag 🌿
- Timeout beachten — Lange Generierungen brauchen lange Connections
- Error-Handling — Was wenn llama-server abstürzt?
- Reconnect-Logik — WebSockets können abbrechen
Für Profis 🌳
- Health-Endpoint — Prüfe llama-server vor dem Start
- Metrics — Tokens/Sekunde, Connection-Count
- Queue — Bei vielen Usern: Request-Queue vor llama-server
🛠️ Tools & Ressourcen
Downloads
| Was | Link |
|---|---|
| Projekt-Code (ZIP) | Download |
| Starter-Projekt | Download |
| Teil 1 (falls nicht gemacht) | Zum Artikel |
Weiterführend
| Ressource | Beschreibung |
|---|---|
| Spring WebSocket Docs | Offizielle Dokumentation |
| WebFlux Guide | Reaktive Programmierung |
| MDN: Server-Sent Events | SSE-Grundlagen |
❓ FAQ — Häufige Fragen
Frage 1: WebSocket vs. Server-Sent Events?
Antwort: SSE ist einfacher, aber nur unidirektional. Für Chat brauchen wir bidirektionale Kommunikation → WebSocket.
Frage 2: Warum ein Backend dazwischen?
Antwort: CORS, Protokoll-Übersetzung, Abstraktion. Später: Auth, Rate-Limiting.
Frage 3: Wie viele gleichzeitige User schafft das?
Antwort: Hängt vom LLM ab, nicht vom Backend. llama-server kann mit --parallel N mehrere Requests parallel verarbeiten.
Frage 4: Funktioniert das auch mit React/Vue/Angular?
Antwort: Ja! Der WebSocket-Code ist Framework-agnostisch. Einfach die JavaScript-Logik übernehmen.
Frage 5: Mein Stream bricht ab — warum?
Antwort: Timeout? Connection closed? Check: Server-Logs, Browser DevTools, Firewall.
Frage 6: Kann ich das auch ohne Spring Boot machen?
Antwort: Ja, mit Javalin, Vert.x, oder plain Servlets. Spring Boot ist hier nicht zwingend.
Frage 7: Hattest du mal einen Demo-Moment, wo alles schiefging?
Antwort: Oh ja. Live-Demo, Kunde im Raum, Streaming funktionierte nicht. Stille. Sehr lange Stille. Manche Geschichten gehören in private logs, nicht in Tech-Blogs. 🔒
📚 Weiter in der Serie
| Teil | Thema | Link |
|---|---|---|
| ✅ 1 | Dein erstes lokales LLM | Zum Artikel |
| ✅ 2 | Streaming — Token für Token | Du bist hier |
| → 3 | Der Kaufberater-Chatbot | Zum Artikel |
| 4 | GPU-Power — CUDA, Metal, Vulkan | Demnächst |
| 5 | Halluzinationen bekämpfen | Demnächst |
| 6+ | RAG mit pgvector | Bei Interesse |
🎯 Zusammenfassung
Das hast du heute gelernt:
- ✅ Server-Sent Events von llama-server verstehen
- ✅ Spring Boot WebSocket-Handler implementieren
- ✅ SSE → WebSocket Protokoll-Übersetzung
- ✅ Frontend mit live-tippender Antwort
Das nimmst du mit:
- Streaming verbessert die UX massiv
- WebSocket für bidirektionale Kommunikation
- Das Backend ist der Proxy zwischen Browser und LLM
💬 Dein Feedback entscheidet!
Streaming funktioniert! Aber das Sprachproblem nervt immer noch, oder?
Nächste Woche: System-Prompts die Deutsch erzwingen. Plus: Kontext-Management, damit der Bot sich an das Gespräch erinnert.
Die Serie lebt von eurem Feedback
Kurzer Reality-Check: Teil 6-8 (RAG mit Vektordatenbank) kommen nur, wenn ihr es wollt.
Ich will wissen:
- Ist das Tempo okay?
- Baust du parallel mit oder liest du nur?
- Was für einen Bot willst DU bauen? Kaufberater? Support? Dokumenten-Suche?
👉 Schreib’s in die Kommentare! Auch „Hat funktioniert!“ oder „Bei Schritt X hing ich fest“ hilft.
📥 Downloads
- 📦 Spring Boot Projekt (ZIP) — Kompletter Code mit Frontend
Fragen? Schreib mir:
- Cassian: cassian@java-developer.online
© 2025 Java Fleet Systems Consulting | java-developer.online
[verwandte_artikele=3]
Tags: #LlamaCpp #Java #SpringBoot #WebSocket #Streaming #LLM #Tutorial