
Von Dr. Cassian Holt, Senior Architect bei Java Fleet Systems Consulting
Schwierigkeit: 🟡 Mittel
Lesezeit: 30 Minuten
Hands-on Zeit: 30 Minuten
Voraussetzungen: Teil 1-3 abgeschlossen, dedizierte GPU (NVIDIA, AMD oder Apple Silicon)
📚 Serie: Lokale KI mit llama.cpp
| Teil | Thema | Status |
|---|---|---|
| 1 | Dein erstes lokales LLM | ✅ Verfügbar |
| 2 | Streaming — Token für Token | ✅ Verfügbar |
| 3 | Der Kaufberater-Chatbot | ✅ Verfügbar |
| → 4 | GPU-Power — CUDA, Metal, Vulkan | Du bist hier |
| 5 | Halluzinationen bekämpfen | Demnächst |
| 6+ | RAG mit pgvector | Bei Interesse |
Neu in der Serie? Starte mit Teil 1 für das grundlegende Setup.
⚡ Das Wichtigste in 30 Sekunden
Dein Problem: Dein Kaufberater funktioniert — aber 5 Sekunden pro Antwort ist zu langsam für echte User.
Die Lösung: GPU-Beschleunigung. Von ~10 Tokens/Sekunde auf 60-100+.
Klassische Anwendungsfälle:
- 🏢 Produktiver Chatbot: Antworten in unter 1 Sekunde — User bleiben dran
- 🧠 Größere Modelle: Mit GPU laufen 7B-Modelle flüssig — viel besseres Deutsch!
Heute lernst du:
- ✅ Welche GPU-Backends llama.cpp unterstützt
- ✅ CUDA für NVIDIA einrichten
- ✅ Metal für Mac aktivieren
- ✅ Vulkan als universelle Lösung
- ✅ Performance messen und optimieren
Für wen ist dieser Artikel?
- 🌱 Anfänger: Du lernst, warum GPUs für LLMs wichtig sind
- 🌿 Erfahrene: Du richtest GPU-Beschleunigung ein
- 🌳 Profis: Im Bonus: Multi-GPU und Layer-Splitting
Zeit-Investment: 30 Minuten bis zur 10x schnelleren Inference
👋 Cassian: „Jetzt wird’s schnell“
Moin! 👋
Drei Teile lang haben wir auf CPU gearbeitet. Das war Absicht — jeder kann mitmachen, egal welche Hardware. Aber mal ehrlich: 10 Tokens pro Sekunde ist… geduldserprobend.
Heute ändern wir das.
Mit GPU-Beschleunigung springen wir von 10 auf 60-100 Tokens pro Sekunde. Das ist der Unterschied zwischen „Demo“ und „Produkt“. Der Unterschied zwischen „Das LLM denkt noch…“ und einer Antwort, die praktisch sofort erscheint.
Bonus: Mit GPU-Power können wir größere Modelle nutzen. Statt dem wackeligen 1.5B-Modell ein solides 7B — das spricht deutlich besseres Deutsch.
Was du brauchst:
- NVIDIA GPU: CUDA (GTX 1060 aufwärts)
- Apple Silicon: Metal (M1/M2/M3)
- AMD GPU: Vulkan oder ROCm
- Intel GPU: Vulkan
Keine dedizierte GPU? Dann ist dieser Teil Theorie für dich — aber lies trotzdem, damit du weißt, was möglich ist.
💡 Reality-Check: Dein „alter“ PC ist nicht veraltet!
Du hast 2022 einen Gaming-PC für 2000-4000€ gekauft? Der hat wahrscheinlich eine RTX 3070, 3080 oder 3090. Das sind MONSTER für lokale LLMs.
Ernsthaft: Eine RTX 3080 von 2022 schlägt für LLM-Inference immer noch die meisten aktuellen Karten. Du brauchst keine RTX 5090. Du brauchst nicht mal eine RTX 4080.
Selbst eine RTX 3060 12GB von 2020 lädt ein 7B-Modell komplett in den VRAM und liefert 50-60 Tokens/Sekunde.
Die Pointe: Während dein PC für die neuesten Spiele vielleicht nicht mehr „Ultra“ schafft, ist er für lokale KI immer noch erste Liga. Die Hardware, die du schon hast, ist wahrscheinlich genau richtig.
Los geht’s.
🖼️ Das Konzept auf einen Blick
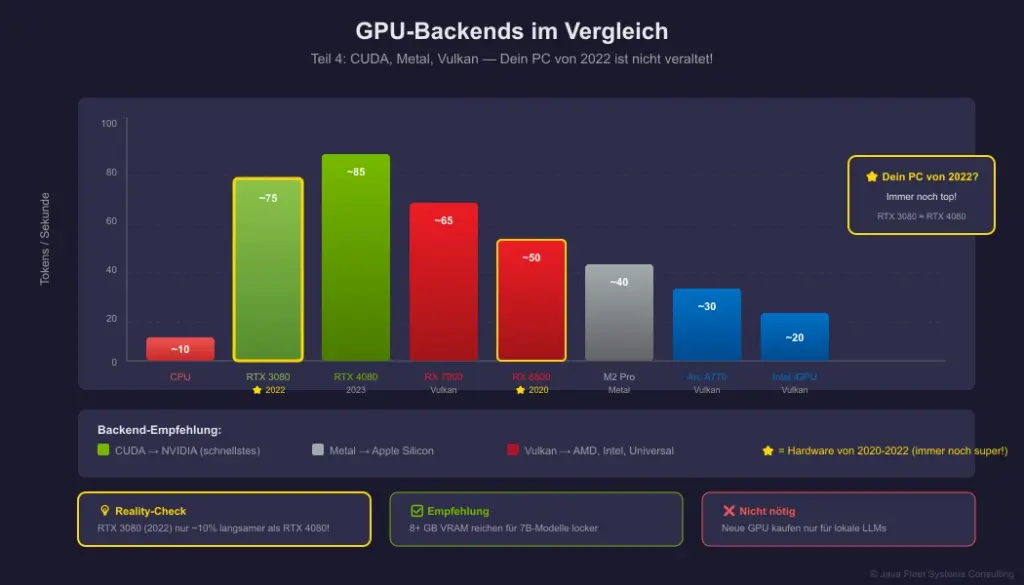
Abbildung 1: Der Performance-Unterschied zwischen CPU und GPU
🟢 GRUNDLAGEN
Warum sind GPUs so viel schneller?
CPUs sind gut in komplexen, sequentiellen Aufgaben. Wenige Kerne, aber sehr schlau.
GPUs sind gut in einfachen, parallelen Aufgaben. Tausende Kerne, die das Gleiche gleichzeitig tun.
LLM-Inference ist perfekt für GPUs:
- Matrix-Multiplikationen (das Herz von Transformern)
- Gleiche Operation auf vielen Daten
- Vorhersagbares Speicherzugriffsmuster
| Hardware | Kerne | Typische LLM-Speed |
|---|---|---|
| CPU (Ryzen 7) | 8-16 | ~10 Tokens/s |
| GPU (RTX 3060) | 3584 | ~60 Tokens/s |
| GPU (RTX 4090) | 16384 | ~150 Tokens/s |
| Apple M2 Pro | 19 GPU-Kerne | ~40 Tokens/s |
Die GPU-Backends von llama.cpp
llama.cpp unterstützt mehrere Backends:
| Backend | Für | Performance | Komplexität |
|---|---|---|---|
| CUDA | NVIDIA GPUs | ⭐⭐⭐⭐⭐ | Mittel |
| Metal | Apple Silicon | ⭐⭐⭐⭐ | Einfach |
| Vulkan | Alle GPUs | ⭐⭐⭐⭐ | Einfach |
| ROCm | AMD GPUs | ⭐⭐⭐⭐ | Komplex |
| SYCL | Intel GPUs | ⭐⭐⭐ | Komplex |
Empfehlung:
- NVIDIA → CUDA
- Mac → Metal (automatisch)
- AMD/Intel/Universal → Vulkan
🟡 PROFESSIONALS
Option 1: NVIDIA CUDA
CUDA ist das schnellste Backend für NVIDIA-Karten.
Voraussetzungen
- NVIDIA-Treiber (aktuell)
- CUDA Toolkit (11.7 oder neuer)
# Prüfe NVIDIA-Treiber nvidia-smi # Sollte zeigen: # NVIDIA-SMI 535.xxx Driver Version: 535.xxx CUDA Version: 12.x
llama.cpp mit CUDA bauen
# Repository klonen (falls nicht vorhanden) git clone https://github.com/ggerganov/llama.cpp cd llama.cpp # Mit CUDA kompilieren make clean make LLAMA_CUDA=1 # Oder mit CMake mkdir build && cd build cmake .. -DLLAMA_CUDA=ON cmake --build . --config Release
Server mit GPU starten
# Alle Layer auf GPU laden ./llama-server -m qwen2.5-1.5b-instruct-q4_k_m.gguf -ngl 99 # -ngl = Number of GPU Layers # 99 = "So viele wie möglich"
Ausgabe bei erfolgreicher GPU-Nutzung:
llm_load_tensors: offloading 24 repeating layers to GPU llm_load_tensors: offloaded 24/25 layers to GPU llm_load_tensors: VRAM used: 1024 MB
Option 2: Apple Metal (Mac)
Auf Apple Silicon ist Metal automatisch aktiv in den Pre-built Binaries.
# Download Pre-built Binary für Mac # Von: https://github.com/ggerganov/llama.cpp/releases # Starten — Metal wird automatisch genutzt ./llama-server -m qwen2.5-1.5b-instruct-q4_k_m.gguf -ngl 99
Prüfen ob Metal aktiv ist:
ggml_metal_init: found device: Apple M2 Pro ggml_metal_init: picking default device: Apple M2 Pro
Option 3: Vulkan (Universal)
Vulkan funktioniert mit fast allen modernen GPUs: NVIDIA, AMD, Intel.
Voraussetzungen
- Vulkan SDK installieren
- Windows: LunarG Vulkan SDK
- Linux:
sudo apt install vulkan-tools libvulkan-dev
- GPU-Treiber mit Vulkan-Support
# Vulkan prüfen vulkaninfo --summary # Sollte deine GPU zeigen
llama.cpp mit Vulkan bauen
cd llama.cpp # Mit Vulkan kompilieren make clean make LLAMA_VULKAN=1 # Oder CMake cmake .. -DLLAMA_VULKAN=ON cmake --build . --config Release
Server starten
./llama-server -m qwen2.5-1.5b-instruct-q4_k_m.gguf -ngl 99
🔬 Performance messen
Benchmark mit llama-bench
# CPU Benchmark ./llama-bench -m qwen2.5-1.5b-instruct-q4_k_m.gguf -ngl 0 # GPU Benchmark ./llama-bench -m qwen2.5-1.5b-instruct-q4_k_m.gguf -ngl 99
Beispiel-Output:
| model | size | ngl | test | t/s | |----------------------|--------|-----|------------|--------| | qwen2.5 1.5B Q4_K_M | 1.1 GB | 0 | pp512 | 45.21 | | qwen2.5 1.5B Q4_K_M | 1.1 GB | 0 | tg128 | 11.34 | | qwen2.5 1.5B Q4_K_M | 1.1 GB | 99 | pp512 | 312.45 | | qwen2.5 1.5B Q4_K_M | 1.1 GB | 99 | tg128 | 67.89 |
- pp512: Prompt Processing (512 Tokens verarbeiten)
- tg128: Text Generation (128 Tokens generieren)
- t/s: Tokens pro Sekunde
Was bedeuten die Zahlen?
| Metrik | CPU | GPU | Verbesserung |
|---|---|---|---|
| Prompt Processing | 45 t/s | 312 t/s | 7x |
| Text Generation | 11 t/s | 68 t/s | 6x |
Das ist der Unterschied zwischen „warten“ und „instant“.
🚀 Größere Modelle mit GPU
Mit GPU-Power können wir endlich größere Modelle nutzen:
Modell-Empfehlungen
| Modell | VRAM | Deutsch | Empfehlung |
|---|---|---|---|
| Qwen2.5-1.5B Q4 | ~1.5 GB | ⭐⭐ | Budget GPU |
| Phi-3 Mini 3.8B Q4 | ~2.5 GB | ⭐⭐⭐ | RTX 3060 6GB |
| Qwen2.5-7B Q4 | ~4.5 GB | ⭐⭐⭐⭐ | RTX 3060 12GB |
| Mistral 7B Q4 | ~4.5 GB | ⭐⭐⭐⭐ | RTX 3060 12GB |
| Llama 3.1 8B Q4 | ~5 GB | ⭐⭐⭐⭐ | RTX 4060 8GB |
7B-Modell ausprobieren
# Download (ca. 4 GB) wget https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-GGUF/resolve/main/qwen2.5-7b-instruct-q4_k_m.gguf # Starten mit GPU ./llama-server -m qwen2.5-7b-instruct-q4_k_m.gguf -ngl 99
Der Unterschied bei Deutsch:
| Modell | Prompt | Antwort |
|---|---|---|
| 1.5B | „Was ist Java?“ | „Java is a programming…“ 😅 |
| 7B | „Was ist Java?“ | „Java ist eine objektorientierte Programmiersprache…“ ✅ |
Mit dem 7B-Modell funktioniert Deutsch zuverlässig — ohne Prompting-Tricks.
🔵 BONUS
Layer Splitting: Wenn VRAM nicht reicht
Was wenn dein Modell 6 GB braucht, aber du nur 4 GB VRAM hast?
Layer Splitting: Ein Teil auf GPU, der Rest auf CPU.
# Nur 20 Layer auf GPU (statt alle) ./llama-server -m qwen2.5-7b-instruct-q4_k_m.gguf -ngl 20
| -ngl | VRAM | Speed | Szenario |
|---|---|---|---|
| 0 | 0 GB | ~10 t/s | Nur CPU |
| 20 | ~3 GB | ~30 t/s | Hybrid |
| 35 | ~5 GB | ~50 t/s | Mehr GPU |
| 99 | ~6 GB | ~70 t/s | Voll GPU |
Faustregel: Mehr Layers auf GPU = schneller, aber mehr VRAM.
Multi-GPU (für die mit Geld)
# Zwei GPUs nutzen ./llama-server -m llama-70b-q4.gguf -ngl 99 --split-mode layer
Das ist für 70B+ Modelle relevant. Bei 7B reicht eine GPU locker.
VRAM-Verbrauch senken
Wenn VRAM knapp ist:
- Kleinere Quantisierung: Q4_K_M → Q3_K_S (weniger Qualität, weniger VRAM)
- Kontext reduzieren:
-c 2048statt Standard 4096 - Batch-Size senken:
-b 256statt 512
./llama-server -m model.gguf -ngl 99 -c 2048 -b 256
💡 Praxis-Tipps
Für Einsteiger 🌱
- Pre-built Binaries nutzen — Selber kompilieren nur wenn nötig
- Mit
-ngl 99starten — llama.cpp nimmt automatisch so viel wie möglich - nvidia-smi beobachten — Zeigt GPU-Auslastung in Echtzeit
Für den Alltag 🌿
- Benchmark vor Production — Miss die tatsächliche Performance
- VRAM-Headroom lassen — 90% Auslastung ist okay, 100% crasht
- Größeres Modell testen — Mit GPU lohnt sich der Sprung auf 7B
Für Profis 🌳
- Flash Attention aktivieren — Schneller bei langen Kontexten
- Quantisierung vergleichen — Q5_K_M vs Q4_K_M vs Q3_K_S
- Monitoring einrichten — GPU-Temperatur, VRAM, Tokens/s
🛠️ Tools & Ressourcen
Downloads
- 📦 Benchmark-Script (ZIP) — Performance-Tests für deine Hardware
- 📄 Qwen2.5-7B-Instruct-GGUF — Empfohlenes 7B-Modell
Weiterführend
| Ressource | Beschreibung |
|---|---|
| llama.cpp GPU Docs | Offizielle Dokumentation |
| CUDA Toolkit Download | NVIDIA CUDA |
| Vulkan SDK | Universal GPU Backend |
❓ FAQ — Häufige Fragen
Frage 1: Welche GPU brauche ich mindestens?
Antwort: Für 1.5B-Modelle: GTX 1060 6GB reicht. Für 7B-Modelle: RTX 3060 12GB empfohlen.
Frage 2: Lohnt sich eine teure GPU für LLMs?
Antwort: Kommt drauf an. RTX 3060 → RTX 4090 ist ~3x schneller, aber 5x teurer. Für die meisten reicht Mittelklasse.
Frage 3: Kann ich meine Laptop-GPU nutzen?
Antwort: Ja, aber mobile GPUs haben weniger VRAM und sind langsamer. Eine GTX 1650 Mobile funktioniert, aber erwarte keine Wunder.
Frage 4: AMD oder NVIDIA?
Antwort: NVIDIA hat besseren Support (CUDA). AMD funktioniert mit Vulkan oder ROCm, aber manchmal hakelig.
Frage 5: Wie viel VRAM brauche ich?
Antwort: Faustregel: Modell-Größe + 20%. Ein 4GB Q4-Modell braucht ~5GB VRAM.
Frage 6: Apple M1/M2 vs. NVIDIA — was ist besser?
Antwort: NVIDIA ist schneller bei gleicher Preisklasse. Aber Apple Silicon ist verdammt gut für den Preis, und Metal „funktioniert einfach“.
Frage 7: Ich habe eine RTX 3080 von 2022 — ist die noch gut genug?
Antwort: Die ist hervorragend. Eine RTX 3080 hat 10GB VRAM und liefert 60-80 Tokens/s. Das reicht für 7B-Modelle locker. Du brauchst keine neue Karte. Ernsthaft: Für LLMs zählt hauptsächlich VRAM, und da sind die 30er-Serie Karten immer noch top.
Frage 8: Mein PC ist von 2020/2021 — soll ich aufrüsten?
Antwort: Wahrscheinlich nicht. Wenn du eine GTX 1080, RTX 2070, oder besser hast: Das reicht für lokale LLMs. Die Karten, die damals gut für Gaming waren, sind heute perfekt für KI. Erst bei 4GB VRAM oder weniger wird’s eng.
📚 Weiter in der Serie
| Teil | Thema | Link |
|---|---|---|
| ✅ 1 | Dein erstes lokales LLM | Zum Artikel |
| ✅ 2 | Streaming — Token für Token | Zum Artikel |
| ✅ 3 | Der Kaufberater-Chatbot | Zum Artikel |
| ✅ 4 | GPU-Power | Du bist hier |
| → 5 | Halluzinationen bekämpfen | Zum Artikel |
| 6+ | RAG mit pgvector | Bei Interesse |
🎯 Zusammenfassung
Das hast du heute gelernt:
- ✅ Warum GPUs für LLMs so viel schneller sind
- ✅ CUDA, Metal und Vulkan einrichten
- ✅ Performance messen und vergleichen
- ✅ Größere Modelle für besseres Deutsch nutzen
Das nimmst du mit:
- GPU-Beschleunigung bringt 5-10x Speedup
- Mit GPU lohnen sich größere Modelle (7B+)
- VRAM ist der limitierende Faktor
- Layer-Splitting als Kompromiss bei wenig VRAM
💬 Dein Feedback entscheidet!
GPU läuft! Der Bot antwortet in unter einer Sekunde. Und mit dem 7B-Modell sogar auf Deutsch.
Aber was, wenn der Bot Quatsch erzählt? Produkte erfindet die es nicht gibt? Fakten halluziniert?
Nächste Woche: Halluzinationen bekämpfen. Websuche als Fakten-Check, RAG-Grundlagen.
Ich will wissen:
- Hast du eine GPU zum Laufen gebracht?
- Wie viel schneller ist es bei dir?
- Welches Modell nutzt du jetzt?
👉 Schreib’s in die Kommentare!
📥 Downloads
- 📦 Benchmark-Script (ZIP) — Performance-Tests
Fragen? Schreib mir:
- Cassian: cassian.holt@java-developer.online
© 2025 Java Fleet Systems Consulting | java-developer.online
📚 Das könnte dich auch interessieren
Tags: #LlamaCpp #Java #GPU #CUDA #Metal #Vulkan #LLM #Tutorial