
Von Elyndra Valen, Senior Entwicklerin bei Java Fleet Systems Consulting
Mit Einblicken von Nova Trent (Junior Dev) und Jamal Hassan (Backend Developer)
Schwierigkeit: 🟡 Mittel
Lesezeit: 40 Minuten
Voraussetzungen: Tag 4 (Lambdas), Tag 5 (Functional Interfaces)
Kurs: Java Erweiterte Techniken – Tag 6 von 10
📖 Java Erweiterte Techniken – Alle Tage
📍 Du bist hier: Tag 6
⚡ Das Wichtigste in 30 Sekunden
Dein Problem: Du hast eine Liste mit 1000 Einträgen. Du willst filtern, transformieren, sortieren und das Ergebnis sammeln. Mit Schleifen wird das schnell unübersichtlich.
Die Lösung: Die Stream-API – deklarativ beschreiben WAS du willst, nicht WIE.
Heute lernst du:
- ✅ Streams erstellen (aus Collections, Arrays, Generatoren)
- ✅ Intermediate Operations:
filter,map,sorted,distinct - ✅ Terminal Operations:
collect,forEach,reduce,count - ✅ Collectors:
toList,toSet,toMap,groupingBy - ✅ Parallel Streams für Performance
Für wen ist dieser Artikel?
- 🌱 Anfänger: Du verstehst endlich, was
.stream().filter().map().collect()macht - 🌿 Erfahrene: Collectors und Reduce meistern
- 🌳 Profis: Parallel Streams, Performance, eigene Collectors
Zeit-Investment: 40 Minuten Lesen + 60-120 Minuten Praxis
👋 Elyndra: „Der Tag, an dem Schleifen obsolet wurden“
Hi! 👋
Elyndra hier für Tag 6. Nach Lambdas und Functional Interfaces kommt jetzt das Herzstück moderner Java-Programmierung: Streams.
Das Problem – klassischer Ansatz:
List<String> namen = List.of("Max", "Anna", "Tom", "Alexandra", "Tim");
// Finde alle Namen mit 'A', mach sie groß, sortiere sie
List<String> ergebnis = new ArrayList<>();
for (String name : namen) {
if (name.contains("A") || name.contains("a")) {
ergebnis.add(name.toUpperCase());
}
}
Collections.sort(ergebnis);
// ergebnis = [ALEXANDRA, ANNA, MAX]
Die Lösung – mit Streams:
List<String> ergebnis = namen.stream()
.filter(name -> name.toLowerCase().contains("a"))
.map(String::toUpperCase)
.sorted()
.toList();
// ergebnis = [ALEXANDRA, ANNA, MAX]
Gleiche Logik, aber:
- ✅ Lesbarer (liest sich wie eine Beschreibung)
- ✅ Weniger Boilerplate
- ✅ Leicht parallelisierbar (
.parallelStream()) - ✅ Kein manuelles Erstellen von Zwischenlisten
💡 Bereit für die Stream-Revolution?
🖼️ Die Stream-Pipeline
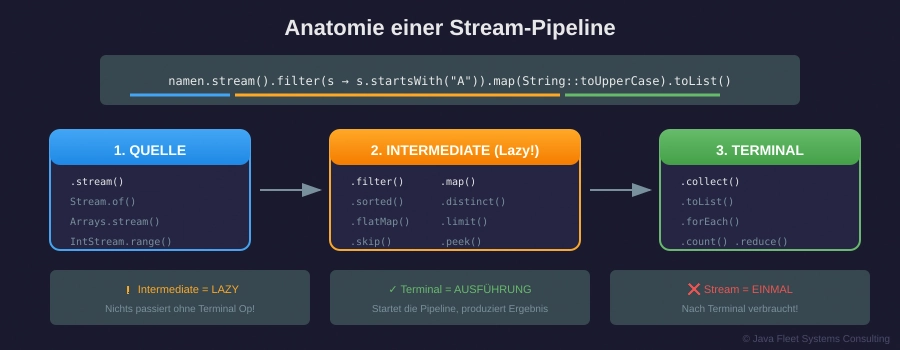
Abbildung 1: Anatomie einer Stream-Pipeline
🟢 GRUNDLAGEN
Was ist ein Stream?
Ein Stream ist eine Sequenz von Elementen, die du mit Operationen verarbeiten kannst. Wichtig:
- ❌ Ein Stream ist keine Datenstruktur (speichert nichts)
- ❌ Ein Stream verändert die Quelle nicht
- ✅ Ein Stream ist lazy (berechnet nur was nötig ist)
- ✅ Ein Stream kann nur einmal durchlaufen werden
List<String> namen = List.of("Max", "Anna", "Tom");
Stream<String> stream = namen.stream(); // Stream erstellen
stream.forEach(System.out::println); // Stream verbrauchen
stream.forEach(System.out::println); // ERROR! Stream bereits verbraucht
Streams erstellen
Aus Collections:
List<String> liste = List.of("A", "B", "C");
Stream<String> stream = liste.stream();
Set<Integer> set = Set.of(1, 2, 3);
Stream<Integer> stream2 = set.stream();
Map<String, Integer> map = Map.of("a", 1, "b", 2);
Stream<Map.Entry<String, Integer>> stream3 = map.entrySet().stream();
Aus Arrays:
String[] array = {"A", "B", "C"};
Stream<String> stream = Arrays.stream(array);
int[] zahlen = {1, 2, 3, 4, 5};
IntStream intStream = Arrays.stream(zahlen);
Aus Werten:
Stream<String> stream = Stream.of("A", "B", "C");
IntStream zahlen = IntStream.of(1, 2, 3, 4, 5);
Generieren:
// Unendlicher Stream! Stream<Double> zufallsZahlen = Stream.generate(Math::random); // Sequenz Stream<Integer> sequenz = Stream.iterate(0, n -> n + 2); // 0, 2, 4, 6, ... // Range (wie Python's range) IntStream range = IntStream.range(0, 10); // 0-9 IntStream rangeClosed = IntStream.rangeClosed(1, 10); // 1-10
Die drei Phasen einer Stream-Pipeline
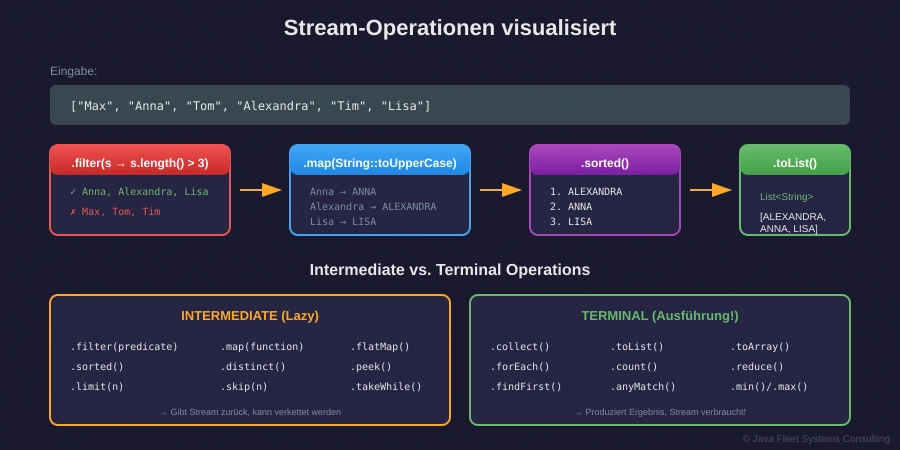
Abbildung 2: Quelle → Intermediate → Terminal
| Phase | Beschreibung | Beispiele |
|---|---|---|
| Quelle | Woher kommen die Daten? | collection.stream(), Stream.of() |
| Intermediate | Transformation (lazy!) | filter(), map(), sorted() |
| Terminal | Ergebnis produzieren | collect(), forEach(), count() |
Wichtig: Intermediate Operations werden erst ausgeführt, wenn eine Terminal Operation aufgerufen wird!
Stream<String> stream = namen.stream()
.filter(s -> {
System.out.println("Filter: " + s); // Wird NICHT ausgegeben!
return s.startsWith("A");
});
// Erst jetzt passiert was:
long count = stream.count(); // Jetzt werden die println ausgeführt
Intermediate Operations
filter() – Elemente filtern
List<Integer> zahlen = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> gerade = zahlen.stream()
.filter(n -> n % 2 == 0)
.toList();
// [2, 4, 6, 8, 10]
map() – Elemente transformieren
List<String> namen = List.of("max", "anna", "tom");
List<String> gross = namen.stream()
.map(String::toUpperCase)
.toList();
// [MAX, ANNA, TOM]
List<Integer> laengen = namen.stream()
.map(String::length)
.toList();
// [3, 4, 3]
flatMap() – Verschachtelte Strukturen flatten
List<List<Integer>> verschachtelt = List.of(
List.of(1, 2, 3),
List.of(4, 5),
List.of(6, 7, 8, 9)
);
List<Integer> flach = verschachtelt.stream()
.flatMap(List::stream)
.toList();
// [1, 2, 3, 4, 5, 6, 7, 8, 9]
sorted() – Sortieren
List<String> namen = List.of("Zebra", "Apfel", "Mango");
List<String> sortiert = namen.stream()
.sorted()
.toList();
// [Apfel, Mango, Zebra]
List<String> nachLaenge = namen.stream()
.sorted(Comparator.comparing(String::length))
.toList();
// [Zebra, Apfel, Mango] oder [Mango, Apfel, Zebra] je nach Stabilität
distinct() – Duplikate entfernen
List<Integer> mitDuplikaten = List.of(1, 2, 2, 3, 3, 3, 4);
List<Integer> unique = mitDuplikaten.stream()
.distinct()
.toList();
// [1, 2, 3, 4]
limit() und skip() – Elemente begrenzen
List<Integer> zahlen = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> ersteDrei = zahlen.stream()
.limit(3)
.toList();
// [1, 2, 3]
List<Integer> ohneDrei = zahlen.stream()
.skip(3)
.toList();
// [4, 5, 6, 7, 8, 9, 10]
// Pagination: Seite 2 (Elemente 4-6)
List<Integer> seite2 = zahlen.stream()
.skip(3)
.limit(3)
.toList();
// [4, 5, 6]
peek() – Debugging
List<String> ergebnis = namen.stream()
.filter(s -> s.startsWith("A"))
.peek(s -> System.out.println("Nach Filter: " + s))
.map(String::toUpperCase)
.peek(s -> System.out.println("Nach Map: " + s))
.toList();
Terminal Operations
collect() – In Collection sammeln
List<String> liste = stream.collect(Collectors.toList()); Set<String> set = stream.collect(Collectors.toSet()); // Seit Java 16: List<String> liste = stream.toList(); // Immutable!
forEach() – Für jedes Element
namen.stream()
.filter(s -> s.startsWith("A"))
.forEach(System.out::println);
count() – Anzahl zählen
long anzahl = namen.stream()
.filter(s -> s.length() > 3)
.count();
findFirst() und findAny() – Element finden
Optional<String> erster = namen.stream()
.filter(s -> s.startsWith("A"))
.findFirst();
erster.ifPresent(System.out::println);
anyMatch(), allMatch(), noneMatch() – Prüfen
boolean hatAnna = namen.stream().anyMatch(s -> s.equals("Anna"));
boolean alleKurz = namen.stream().allMatch(s -> s.length() < 10);
boolean keinerLeer = namen.stream().noneMatch(String::isEmpty);
min() und max()
Optional<String> laengster = namen.stream()
.max(Comparator.comparing(String::length));
Optional<Integer> minimum = zahlen.stream()
.min(Integer::compareTo);
🟡 PROFESSIONALS
Collectors – Die Sammler-Werkzeugkiste
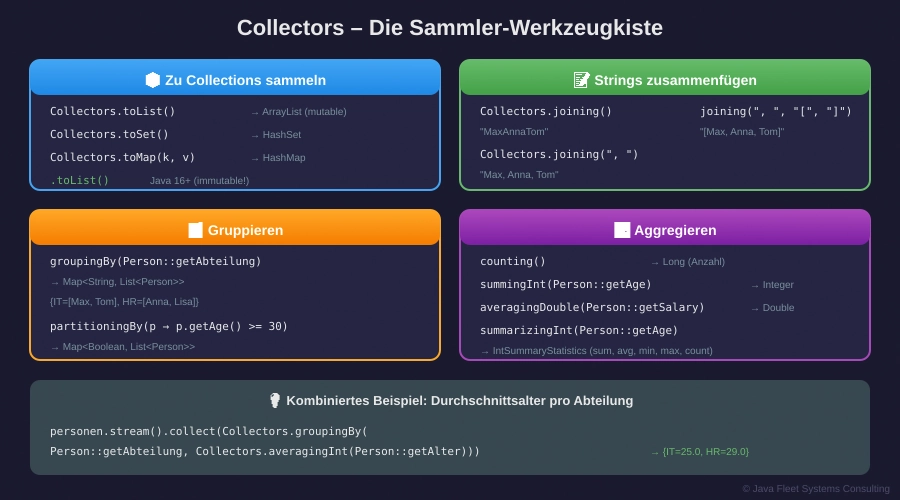
Abbildung 3: Die wichtigsten Collectors
toList(), toSet(), toCollection()
List<String> liste = stream.collect(Collectors.toList()); Set<String> set = stream.collect(Collectors.toSet()); TreeSet<String> treeSet = stream.collect(Collectors.toCollection(TreeSet::new));
toMap()
// Name -> Länge
Map<String, Integer> nameLaenge = namen.stream()
.collect(Collectors.toMap(
name -> name, // Key
name -> name.length() // Value
));
// {Max=3, Anna=4, Tom=3}
// Mit Function.identity()
Map<String, Integer> nameLaenge2 = namen.stream()
.collect(Collectors.toMap(
Function.identity(),
String::length
));
joining()
String joined = namen.stream()
.collect(Collectors.joining());
// "MaxAnnaTom"
String mitKomma = namen.stream()
.collect(Collectors.joining(", "));
// "Max, Anna, Tom"
String mitKlammern = namen.stream()
.collect(Collectors.joining(", ", "[", "]"));
// "[Max, Anna, Tom]"
groupingBy() – Gruppieren
List<Person> personen = List.of(
new Person("Max", 25, "IT"),
new Person("Anna", 30, "HR"),
new Person("Tom", 25, "IT"),
new Person("Lisa", 28, "HR")
);
// Nach Abteilung gruppieren
Map<String, List<Person>> nachAbteilung = personen.stream()
.collect(Collectors.groupingBy(Person::getAbteilung));
// {IT=[Max, Tom], HR=[Anna, Lisa]}
// Nach Alter gruppieren, nur Namen sammeln
Map<Integer, List<String>> namenNachAlter = personen.stream()
.collect(Collectors.groupingBy(
Person::getAlter,
Collectors.mapping(Person::getName, Collectors.toList())
));
// {25=[Max, Tom], 28=[Lisa], 30=[Anna]}
partitioningBy() – In zwei Gruppen teilen
Map<Boolean, List<Person>> partition = personen.stream()
.collect(Collectors.partitioningBy(p -> p.getAlter() >= 28));
// {true=[Anna, Lisa], false=[Max, Tom]}
counting(), summingInt(), averagingDouble()
// Anzahl pro Abteilung
Map<String, Long> anzahlProAbteilung = personen.stream()
.collect(Collectors.groupingBy(
Person::getAbteilung,
Collectors.counting()
));
// {IT=2, HR=2}
// Durchschnittsalter pro Abteilung
Map<String, Double> durchschnittProAbteilung = personen.stream()
.collect(Collectors.groupingBy(
Person::getAbteilung,
Collectors.averagingInt(Person::getAlter)
));
// {IT=25.0, HR=29.0}
reduce() – Alles auf einen Wert reduzieren
List<Integer> zahlen = List.of(1, 2, 3, 4, 5);
// Summe
int summe = zahlen.stream()
.reduce(0, (a, b) -> a + b);
// 15
// Mit Method Reference
int summe2 = zahlen.stream()
.reduce(0, Integer::sum);
// 15
// Ohne Startwert (gibt Optional zurück)
Optional<Integer> summe3 = zahlen.stream()
.reduce(Integer::sum);
// Maximum
Optional<Integer> max = zahlen.stream()
.reduce(Integer::max);
// String zusammenbauen
String concat = namen.stream()
.reduce("", (a, b) -> a + b);
Die reduce-Signatur verstehen:
T reduce(T identity, BinaryOperator<T> accumulator) // Startwert (bisheriges Ergebnis, nächstes Element) -> neues Ergebnis
Primitive Streams: IntStream, LongStream, DoubleStream
Für Performance bei primitiven Typen:
// IntStream
int summe = IntStream.rangeClosed(1, 100).sum(); // 5050
IntSummaryStatistics stats = IntStream.of(1, 2, 3, 4, 5)
.summaryStatistics();
System.out.println("Sum: " + stats.getSum()); // 15
System.out.println("Avg: " + stats.getAverage()); // 3.0
System.out.println("Max: " + stats.getMax()); // 5
System.out.println("Min: " + stats.getMin()); // 1
System.out.println("Count: " + stats.getCount()); // 5
// Konvertieren
IntStream intStream = namen.stream()
.mapToInt(String::length);
Stream<Integer> boxed = intStream.boxed();
Parallel Streams
// Sequentiell
long count1 = liste.stream()
.filter(expensiveOperation)
.count();
// Parallel – nutzt alle CPU-Kerne
long count2 = liste.parallelStream()
.filter(expensiveOperation)
.count();
// Oder später parallelisieren
long count3 = liste.stream()
.parallel()
.filter(expensiveOperation)
.count();
Wann Parallel Streams nutzen?
| ✅ Sinnvoll | ❌ Nicht sinnvoll |
|---|---|
| Große Datenmengen (>10.000) | Kleine Listen |
| CPU-intensive Operationen | I/O-lastige Operationen |
| Unabhängige Operationen | Operationen mit Seiteneffekten |
| ArrayList, Arrays | LinkedList, TreeSet |
⚠️ Vorsicht: Parallel Streams sind nicht automatisch schneller! Der Overhead kann bei kleinen Datenmengen größer sein als der Gewinn.
🔵 BONUS
Optional mit Streams
Optional<Person> aelteste = personen.stream()
.max(Comparator.comparing(Person::getAlter));
// Optional-Kette
String name = aelteste
.map(Person::getName)
.map(String::toUpperCase)
.orElse("Niemand");
Eigene Collector erstellen
// Collector der einen String mit Komma und "und" baut
// [A, B, C] -> "A, B und C"
Collector<String, ?, String> oxfordComma = Collector.of(
ArrayList::new, // Supplier
ArrayList::add, // Accumulator
(left, right) -> { left.addAll(right); return left; }, // Combiner
list -> { // Finisher
if (list.isEmpty()) return "";
if (list.size() == 1) return list.get(0);
return String.join(", ", list.subList(0, list.size() - 1))
+ " und " + list.get(list.size() - 1);
}
);
String result = Stream.of("Max", "Anna", "Tom")
.collect(oxfordComma);
// "Max, Anna und Tom"
💬 Real Talk: Stream-Fallen vermeiden
Java Fleet Büro, Mittwoch 16:00. Code Review.
Tom: „Jamal, mein Stream funktioniert nicht. Er macht einfach… nichts?“
namen.stream()
.filter(s -> s.startsWith("A"))
.map(String::toUpperCase);
// Nichts passiert!
Jamal: „Klassiker! Du hast keine Terminal Operation. Streams sind lazy – ohne collect(), forEach() oder ähnliches passiert gar nichts.“
Tom: „Ah! Und was ist hiermit?“
Stream<String> stream = namen.stream().filter(s -> s.startsWith("A"));
stream.count();
stream.forEach(System.out::println); // ERROR!
Jamal: „Ein Stream kann nur einmal konsumiert werden. Nach count() ist er verbraucht.“
Nova: kommt dazu „Ich hab noch einen: Warum ist mein Parallel Stream langsamer als der normale?“
List<String> klein = List.of("A", "B", "C");
klein.parallelStream().map(s -> s + "!").toList(); // Langsamer!
Jamal: „Parallel Streams haben Overhead – Thread-Pool, Splitting, Merging. Bei drei Elementen ist der Overhead größer als der Gewinn. Parallel lohnt sich erst ab ~10.000 Elementen.“
Elyndra: nickt „Goldene Regel: Miss zuerst, optimiere dann. Nicht blind .parallelStream() überall reinhauen.“
❓ FAQ
Frage 1: Stream vs. for-Schleife – was ist schneller?
Bei kleinen Mengen: for-Schleife (kein Overhead).
Bei großen Mengen: ungefähr gleich, Streams manchmal etwas langsamer.
Bei paralleler Verarbeitung: Parallel Streams können schneller sein.
Aber: Streams sind oft lesbarer und wartbarer. Lesbarkeit > Mikro-Optimierung!
Frage 2: Kann ich einen Stream mehrfach verwenden?
Nein! Ein Stream kann nur einmal durchlaufen werden. Wenn du ihn mehrfach brauchst, erstelle ihn neu oder sammle die Daten in einer Collection.
Supplier<Stream<String>> streamSupplier = () -> namen.stream().filter(s -> s.startsWith("A"));
long count = streamSupplier.get().count();
List<String> list = streamSupplier.get().toList();
Frage 3: toList() vs. collect(Collectors.toList())?
toList() (Java 16+) | collect(Collectors.toList()) |
|---|---|
| Gibt immutable Liste zurück | Gibt mutable ArrayList zurück |
| Kürzer | Länger |
| Null-Elemente erlaubt | Null-Elemente erlaubt |
Frage 4: Wann flatMap statt map?
Wenn deine Transformation eine Collection zurückgibt und du eine flache Liste willst:
// map: Stream<List<String>> – verschachtelt!
Stream<List<String>> nested = personen.stream()
.map(Person::getHobbies);
// flatMap: Stream<String> – flach!
Stream<String> flat = personen.stream()
.flatMap(p -> p.getHobbies().stream());
Frage 5: Bernd sagt, Streams seien „nur fancy Schleifen“?
seufz Bernd unterschätzt mal wieder:
- Deklarativ statt imperativ (WAS nicht WIE)
- Lazy Evaluation (nur berechnen was nötig ist)
- Einfache Parallelisierung (
.parallelStream()) - Funktionskomposition (Filter + Map + Sort als Pipeline)
- Keine Zwischenvariablen nötig
🔍 „behind the code“ oder „in my feels“? Die echten Geschichten findest du, wenn du weißt wo du suchen musst…
🎁 Cheat Sheet
🟢 Stream erstellen
collection.stream()
Arrays.stream(array)
Stream.of("A", "B", "C")
Stream.generate(supplier)
Stream.iterate(seed, operator)
IntStream.range(0, 10)
IntStream.rangeClosed(1, 10)
🟡 Intermediate Operations
.filter(predicate) // Filtern .map(function) // Transformieren .flatMap(function) // Flatten .sorted() // Sortieren .sorted(comparator) // Mit Comparator .distinct() // Duplikate weg .limit(n) // Erste n .skip(n) // Erste n überspringen .peek(consumer) // Debugging
🔵 Terminal Operations
.collect(collector) // Sammeln .toList() // Zu List (Java 16+) .forEach(consumer) // Für jedes Element .count() // Anzahl .findFirst() // Erstes Optional .findAny() // Irgendeins Optional .anyMatch(predicate) // Mindestens eins? .allMatch(predicate) // Alle? .noneMatch(predicate) // Keins? .reduce(identity, op) // Reduzieren .min(comparator) // Minimum .max(comparator) // Maximum
🔴 Collectors
Collectors.toList() Collectors.toSet() Collectors.toMap(keyFn, valueFn) Collectors.joining(delimiter) Collectors.groupingBy(classifier) Collectors.partitioningBy(predicate) Collectors.counting() Collectors.summingInt(mapper) Collectors.averagingDouble(mapper)
🎨 Challenge für dich!
🟢 Level 1 – Einsteiger
- [ ] Filtere alle Zahlen > 5 und verdopple sie
- [ ] Finde den längsten Namen in einer Liste
- [ ] Zähle wie viele Strings mit „A“ beginnen
Geschätzte Zeit: 20-30 Minuten
🟡 Level 2 – Fortgeschritten
- [ ] Gruppiere Personen nach Alter
- [ ] Berechne Durchschnittsalter pro Abteilung
- [ ] Baue einen CSV-String aus einer Liste von Objekten
Geschätzte Zeit: 45-60 Minuten
🔵 Level 3 – Profi
- [ ] Implementiere Pagination mit skip/limit
- [ ] Schreibe einen Custom Collector
- [ ] Vergleiche Performance: Stream vs. for vs. parallelStream
Geschätzte Zeit: 60-90 Minuten
Java Erweiterte Techniken - Tag 6
Stream-API
📦 Downloads
🔗 Weiterführende Links
🇩🇪 Deutsch
| Ressource | Beschreibung |
|---|---|
| Rheinwerk: Streams | Umfassendes Kapitel |
🇬🇧 Englisch
| Ressource | Beschreibung | Level |
|---|---|---|
| Oracle: Stream Tutorial | Offizielle Doku | 🟢 |
| Baeldung: Java Streams | Praxisbeispiele | 🟡 |
| Baeldung: Collectors | Deep Dive | 🟡 |
📧 Offizielle Dokumentation
👋 Geschafft! 🎉
Was du heute gelernt hast:
✅ Streams = Lazy, deklarative Datenverarbeitung
✅ Die drei Phasen: Quelle → Intermediate → Terminal
✅ filter, map, sorted, distinct für Transformation
✅ collect, forEach, reduce für Ergebnisse
✅ Collectors für komplexe Aggregationen
✅ Parallel Streams (mit Vorsicht!)
Fragen? elyndra.valen@java-developer.online
📖 Weiter geht’s!
← Vorheriger Tag: Tag 5: Functional Interfaces
→ Nächster Tag: Tag 7: File I/O
Tags: #Java #Streams #StreamAPI #Collectors #FunctionalProgramming #Tutorial
📚 Das könnte dich auch interessieren
© 2025 Java Fleet Systems Consulting | java-developer.online