
Java Anwendungsentwicklung – Tag 7 von 10
Von Franz-Martin, CTO bei Java Fleet Systems Consulting
Schwierigkeit: 🟡 Fortgeschritten
Voraussetzungen: Tag 6 (JDBC Grundlagen) abgeschlossen
🗺️ Deine Position im Kurs
| Tag | Thema | Niveau | Status |
|---|---|---|---|
| 1 | Die Desktop-Ära: Warum GUIs? | 🟢 Grundlagen | ✅ Abgeschlossen |
| 2 | AWT & Swing Grundlagen | 🟢 Grundlagen | ✅ Abgeschlossen |
| 3 | Layouts & Event-Handling | 🟢 Grundlagen | ✅ Abgeschlossen |
| 4 | Komplexe Swing-Komponenten | 🟡 Fortgeschritten | ✅ Abgeschlossen |
| 5 | JavaFX: Die „moderne“ Alternative | 🔴 KOPFNUSS | ✅ Abgeschlossen |
| 6 | JDBC Grundlagen | 🟢 Grundlagen | ✅ Abgeschlossen |
| → 7 | JDBC Best Practices | 🟡 Fortgeschritten | 👉 DU BIST HIER! |
| 8 | JPA Einführung | 🟢 Grundlagen | 🔜 Kommt als nächstes |
| 9 | JPA CRUD & Queries | 🟡 Fortgeschritten | 🔒 Gesperrt |
| 10 | Integration & Ausblick | 🔴 KOPFNUSS | 🔒 Gesperrt |
Legende: 🟢 Einsteiger-freundlich | 🟡 Erfordert Grundlagen | 🔴 Optional/Anspruchsvoll
⚡ Das Wichtigste in 30 Sekunden
Gestern: JDBC funktioniert.
Heute: JDBC in Produktion.
Die drei Säulen produktionsreifer JDBC-Anwendungen:
- Connection Pooling → Performance (100x schneller!)
- Transactions → Datenintegrität (Alles oder Nichts)
- DAO Pattern → Saubere Architektur (Wartbarkeit)
🟢 GRUNDLAGEN: Connection Pooling
Das Problem ohne Pool
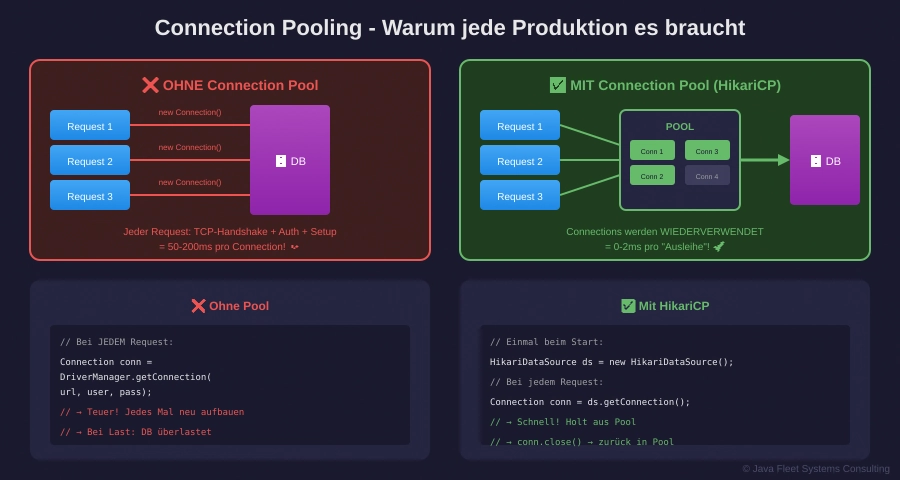
Abbildung 1: Ohne Pool ist jede Connection teuer – Mit Pool sind sie sofort verfügbar
Ohne Pool: Jeder Request baut eine neue Connection auf.
// Bei JEDEM Request: Connection conn = DriverManager.getConnection(url, user, pass); // → TCP-Handshake + Authentifizierung + Setup = 50-200ms!
Das summiert sich:
- 100 Requests/Sekunde × 100ms = 10 Sekunden reine Wartezeit!
- Plus: Datenbank hat nur begrenzte Connections
Mit Pool: Connections werden wiederverwendet.
// Einmal beim Start: HikariDataSource dataSource = new HikariDataSource(config); // Bei JEDEM Request: Connection conn = dataSource.getConnection(); // ~0-2ms! // ... conn.close(); // Gibt zurück in den Pool, schließt NICHT!
HikariCP konfigurieren
HikariCP ist der Standard – Spring Boot verwendet ihn automatisch.
HikariConfig config = new HikariConfig();
// Verbindungsdaten
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");
config.setUsername("user");
config.setPassword("pass");
// Pool-Größe
config.setMaximumPoolSize(10); // Max 10 Connections gleichzeitig
config.setMinimumIdle(2); // Min 2 immer bereit
// Timeouts
config.setConnectionTimeout(30000); // 30s warten auf Connection
config.setIdleTimeout(600000); // 10min bis idle geschlossen
config.setMaxLifetime(1800000); // 30min max Lebenszeit
// Pool erstellen
HikariDataSource dataSource = new HikariDataSource(config);
Faustregel für Pool-Größe:
connections = (core_count * 2) + effective_spindle_count
Teil Bedeutung core_count Anzahl CPU-Kerne *2 Weil Threads bei I/O warten (Hyper-Threading-Effekt) effective_spindle_count Anzahl Festplatten/SSDs (bei SSD meist 1) Für die meisten Apps: 10-20 Connections reichen!
🟡 PROFESSIONALS: Transactions
Warum Transactions?
Abbildung 2: Ohne Transaction kann Geld „verschwinden“
Das klassische Beispiel: Banküberweisung.
// OHNE Transaction - GEFÄHRLICH!
stmt.executeUpdate("UPDATE konto SET stand=stand-100 WHERE id='A'");
// 💥 Server crasht hier!
stmt.executeUpdate("UPDATE konto SET stand=stand+100 WHERE id='B'");
// → 100€ verschwunden!
Mit Transaction:
conn.setAutoCommit(false); // ⚠️ WICHTIG!
try {
stmt.executeUpdate("UPDATE konto SET stand=stand-100 WHERE id='A'");
// 💥 Server crasht hier!
stmt.executeUpdate("UPDATE konto SET stand=stand+100 WHERE id='B'");
conn.commit(); // ✅ Beide Änderungen werden gespeichert
} catch (Exception e) {
conn.rollback(); // 🔙 Alle Änderungen rückgängig!
throw e;
} finally {
conn.setAutoCommit(true); // Wichtig für den Pool!
}
ACID – Die 4 Garantien
| Buchstabe | Bedeutung | Erklärung |
|---|---|---|
| A | Atomicity | Alles oder nichts |
| C | Consistency | DB bleibt in konsistentem Zustand |
| I | Isolation | Transaktionen beeinflussen sich nicht |
| D | Durability | Nach Commit ist es dauerhaft |
🟡 Das DAO Pattern
Warum DAO?
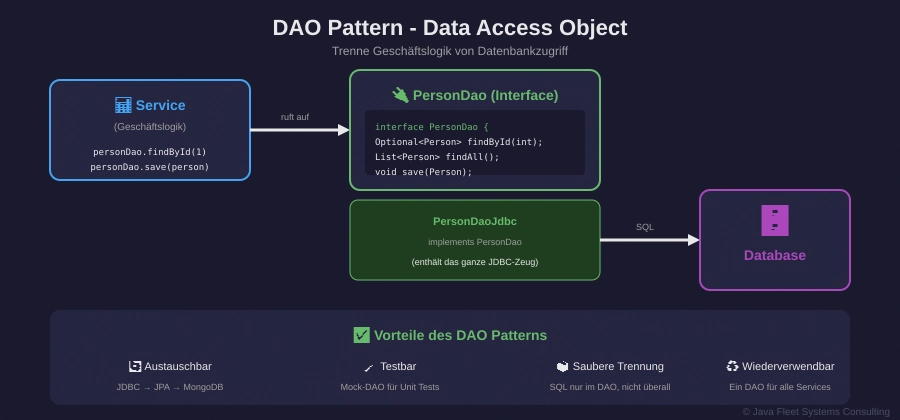
Abbildung 3: DAO trennt Geschäftslogik von Datenbankzugriff
Ohne DAO: SQL überall verstreut.
// In PersonService.java String sql = "SELECT * FROM personen WHERE..."; // In BestellService.java String sql = "SELECT * FROM personen JOIN..."; // In ReportService.java String sql = "SELECT name FROM personen WHERE..."; // → Chaos! Änderungen an der Tabelle = überall suchen
Mit DAO: SQL nur an einer Stelle.
// PersonDao Interface
public interface PersonDao {
Optional<Person> findById(int id);
List<Person> findAll();
Person save(Person person);
boolean update(Person person);
boolean deleteById(int id);
}
// Service-Code - KEIN SQL!
public class PersonService {
private final PersonDao personDao;
public Person registrieren(String name, int alter) {
Person person = new Person(name, alter, null);
return personDao.save(person); // SQL ist im DAO gekapselt!
}
}
Die Implementation
public class PersonDaoJdbc implements PersonDao {
private final DataSource dataSource;
public PersonDaoJdbc(DataSource dataSource) {
this.dataSource = dataSource; // Dependency Injection!
}
@Override
public Optional<Person> findById(int id) {
String sql = "SELECT id, name, alter, email FROM personen WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setInt(1, id);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
return Optional.of(mapRow(rs));
}
}
} catch (SQLException e) {
throw new DaoException("Fehler beim Laden", e);
}
return Optional.empty();
}
// Row Mapper - zentralisiert!
private Person mapRow(ResultSet rs) throws SQLException {
return new Person(
rs.getInt("id"),
rs.getString("name"),
rs.getInt("alter"),
rs.getString("email")
);
}
}
Vorteile des DAO Patterns
| Vorteil | Erklärung |
|---|---|
| 🔄 Austauschbar | JDBC → JPA → MongoDB ohne Service-Änderung |
| 🧪 Testbar | Mock-DAO für Unit Tests |
| 📦 Saubere Trennung | SQL nur im DAO |
| ♻️ Wiederverwendbar | Ein DAO für alle Services |
💬 Real Talk: Der Performance-Bug
Java Fleet Büro, Montag 9:00 Uhr.
Code Sentinel: „Franz-Martin, die Produktion ist langsam. Sehr langsam.“
Franz-Martin: „Wie langsam?“
Code Sentinel: „Requests brauchen 3-5 Sekunden. Vorher waren es 200ms.“
Franz-Martin: „Was hat sich geändert?“
Code Sentinel: „Nova hat letzte Woche das neue Reporting-Feature deployed.“
Franz-Martin: „Nova, zeig mal den Code.“
Nova: (nervös) „Hier… für jeden Report hole ich die Daten einzeln…“
for (Person person : allePersonen) {
Connection conn = DriverManager.getConnection(url, user, pass);
// ... Query ...
conn.close();
}
Franz-Martin: „Da ist das Problem. 1000 Personen = 1000 neue Connections.“
Nova: „Aber ich schließe sie doch!“
Franz-Martin: „Schließen ist nicht das Problem. Das AUFBAUEN dauert. Jede Connection: TCP-Handshake, SSL, Authentifizierung…“
Nova: „Wie fix ich das?“
Franz-Martin: „Connection Pool. Eine Connection aus dem Pool holen dauert Mikrosekunden, nicht Millisekunden.“
// Einmal beim Start
HikariDataSource ds = new HikariDataSource(config);
// Im Loop
for (Person person : allePersonen) {
Connection conn = ds.getConnection(); // Aus dem Pool!
// ... Query ...
conn.close(); // Zurück in den Pool!
}
Nova: „Das war’s?“
Franz-Martin: „Das war’s. Aber noch besser: Hol ALLE Personen in EINER Query statt 1000 einzelne.“
Nova: „Oh… SELECT * FROM personen WHERE id IN (…)?“
Franz-Martin: „Genau. Das nennt sich ‚N+1 Problem‘. Wirst du noch öfter sehen.“
✅ Checkpoint
📝 Quiz
Frage 1: Was ist der Hauptvorteil von Connection Pooling?
A) Mehr Sicherheit
B) Weniger Code
C) Connections werden wiederverwendet statt neu erstellt
D) Automatische Transaktionen
Frage 2: Was passiert bei conn.close() wenn die Connection aus einem Pool kommt?
A) Die Connection wird geschlossen
B) Die Connection wird zurück in den Pool gegeben
C) Ein Fehler wird geworfen
D) Nichts
Frage 3: Wann sollte man conn.rollback() aufrufen?
A) Nach jedem erfolgreichen Statement
B) Vor commit()
C) Wenn ein Fehler auftritt und die Änderungen rückgängig gemacht werden sollen
D) Nie, das macht JDBC automatisch
Frage 4: Was ist der Hauptzweck des DAO Patterns?
A) Performance verbessern
B) Datenbankzugriff von Geschäftslogik trennen
C) SQL automatisch generieren
D) Connection Pooling implementieren
📝 Quiz-Lösungen
Frage 1: ✅ C – Connections werden wiederverwendet
Das Erstellen neuer Connections ist teuer (50-200ms). Pool: <2ms.
Frage 2: ✅ B – Zurück in den Pool
Der Pool „täuscht“ das Schließen vor. Die Connection bleibt offen für den nächsten Request.
Frage 3: ✅ C – Bei Fehlern
Rollback macht alle Änderungen seit dem letzten Commit rückgängig.
Frage 4: ✅ B – Trennung von Datenbankzugriff und Geschäftslogik
Der Service-Code sieht kein SQL. Das DAO kapselt alles.
❓ FAQ
Wie groß sollte mein Connection Pool sein?
Faustregel: (CPU-Kerne × 2) + Anzahl Festplatten. Für die meisten Apps: 10-20 reichen. Mehr Connections ≠ mehr Performance!
Muss ich Transactions immer manuell steuern?
In reinem JDBC: Ja. Mit Spring: Nein, @Transactional macht das automatisch. JPA hat auch eigene Transaction-Verwaltung.
Warum HikariCP und nicht C3P0 oder DBCP?
HikariCP ist schneller, hat weniger Bugs, und ist der Spring Boot Default. Benchmark: HikariCP schlägt alle anderen um Faktor 2-10.
Wann DAO, wann Repository Pattern?
DAO = feingranulare CRUD-Operationen. Repository = Domain-orientiert (Aggregate Roots). In der Praxis oft synonym verwendet.
Muss ich für jede Tabelle ein DAO schreiben?
Mit JDBC: Ja, das ist viel Boilerplate. Mit JPA: JpaRepository<Entity, ID> und fertig. Das zeigen wir in Tag 8-9!
📦 Downloads
Quick Start:
mvn exec:java # Connection Pool Demo mvn exec:java -Ptransaction # Transaction Demo mvn exec:java -Pdao # DAO Pattern Demo
🔗 Weiterführende Links
| Ressource | Beschreibung |
|---|---|
| HikariCP | Der schnellste Connection Pool |
| DAO Pattern (Oracle) | Offizielle Dokumentation |
| ACID (Wikipedia) | Transaction-Garantien |
🎉 Tag 7 geschafft!
Was du heute gelernt hast:
✅ Connection Pooling mit HikariCP (100x schneller!)
✅ Transactions für Datenintegrität (commit/rollback)
✅ ACID-Prinzipien verstehen
✅ DAO Pattern für saubere Architektur
✅ Dependency Injection für DAOs
Morgen – Tag 8: JPA Einführung
Schluss mit dem JDBC-Boilerplate! JPA generiert SQL automatisch und macht PersonDaoJdbc zu einer einzigen Zeile.
Fragen? franz-martin@java-developer.online
© 2026 Java Fleet Systems Consulting | java-developer.online