
Java Web Aufbau – Tag 7 von 10
Von Elyndra Valen, Senior Developer bei Java Fleet Systems Consulting
📋 Deine Position im Kurs
| Tag | Thema | Status |
|---|---|---|
| 1 | Filter im Webcontainer | ✅ Abgeschlossen |
| 2 | Listener im Webcontainer | ✅ Abgeschlossen |
| 3 | Authentifizierung über Datenbank | ✅ Abgeschlossen |
| 4 | Container-Managed Security & Jakarta Security API | ✅ Abgeschlossen |
| 5 | Custom Tags & Tag Handler (SimpleTag) | ✅ Abgeschlossen |
| 6 | Custom Tag Handler mit BodyTagSupport | ✅ Abgeschlossen |
| → 7 | JPA vs JDBC – Konfiguration & Provider | 👉 DU BIST HIER! |
| 8 | JPA Relationen (1): @OneToOne & @ManyToOne | 🔒 Noch nicht freigeschaltet |
| 9 | JPA Relationen (2): @OneToMany & @ManyToMany | 🔒 Noch nicht freigeschaltet |
| 10 | JSF Überblick – Component-Based UI | 🔒 Noch nicht freigeschaltet |
Modul: Java Web Aufbau
Gesamt-Dauer: 10 Arbeitstage
Dein Ziel: JPA verstehen, konfigurieren und erste Entities erstellen
📋 Voraussetzungen für diesen Tag
Du brauchst:
- ✅ JDK 21 LTS installiert
- ✅ Apache NetBeans 22 (oder neuer)
- ✅ Payara Server 6.x konfiguriert
- ✅ MySQL oder PostgreSQL Datenbank
- ✅ Tag 1-6 abgeschlossen
- ✅ JDBC Grundlagen (aus Java SE)
Datenbank-Setup:
docker run --name mysql-jpa -e MYSQL_ROOT_PASSWORD=secret \ -e MYSQL_DATABASE=jpadb -p 3306:3306 -d mysql:8
Tag verpasst?
Kein Problem! Spring zurück zu Tag 6 für BodyTagSupport Basics.
Setup-Probleme?
Schreib uns: support@java-developer.online
⚡ Das Wichtigste in 30 Sekunden
Heute lernst du:
- ✅ Was JPA ist und der Unterschied zu JDBC
- ✅ persistence.xml konfigurieren
- ✅ EntityManager für CRUD nutzen
- ✅ Entity-Klassen mit @Entity, @Id, @Column erstellen
- ✅ JPA-Provider (Hibernate) einrichten
Am Ende des Tages kannst du: Datenbankzugriffe ohne SQL schreiben, Entity-Klassen designen und production-ready Persistence Layer aufbauen.
Schwierigkeitsgrad: Mittel (aber Game-Changer!)
👋 Willkommen zu Tag 7!
Hi! 👋
Elyndra hier. Heute wird’s richtig spannend!
Kurzwiederholung: Challenge von Tag 6
Gestern solltest du BodyTagSupport-Tags mit Iteration erstellen. Falls noch nicht gemacht – die Lösung findest du im hier.
Was du heute lernst:
Nach 6 Tagen Servlets, JSP und Custom Tags kommt der Game-Changer: JPA – Jakarta Persistence API.
„Warum brauche ich JPA, wenn ich JDBC kann?“, fragst du dich vielleicht?
Real talk: JDBC ist wie mit Schraubenzieher ein Haus bauen. Geht. Aber JPA ist die elektrische Bohrmaschine – schneller, effizienter, weniger fehleranfällig.
Was JPA dir gibt:
- ✅ Keine SQL-Queries mehr schreiben (meist!)
- ✅ Object-Relational Mapping (Java-Objekte = DB-Rows)
- ✅ Automatisches Schema Management
- ✅ Transaction Management integriert
- ✅ Caching out-of-the-box
Keine Sorge:
JPA wirkt „magisch“ mit Annotations und XML. Aber ich zeige dir genau, was passiert!
Los geht’s! 🚀
🟢 GRUNDLAGEN: Was ist JPA?
Definition
JPA = Jakarta Persistence API – eine Spezifikation für Object-Relational Mapping (ORM).
Wichtig: JPA ist NICHT eine Implementierung! Es ist ein Standard, ähnlich wie JDBC.
JPA (Spezifikation) ↓ implementiert von: ├── Hibernate (populärster Provider) ├── EclipseLink (Referenzimplementierung) └── OpenJPA
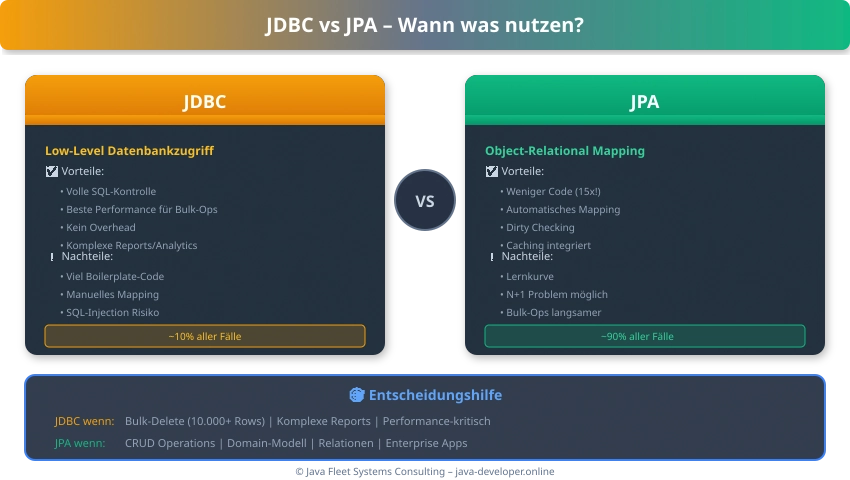
JDBC vs. JPA – Der Vergleich
Mit JDBC (der alte Weg):
String sql = "SELECT id, name, email FROM users WHERE id = ?";
try (PreparedStatement stmt = conn.prepareStatement(sql)) {
stmt.setInt(1, userId);
ResultSet rs = stmt.executeQuery();
if (rs.next()) {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
user.setEmail(rs.getString("email"));
return user;
}
}
Mit JPA (der moderne Weg):
User user = entityManager.find(User.class, userId);
Das war’s! Eine Zeile statt 15. JPA macht das SQL, Mapping und Connection-Handling für dich.
Wann JDBC? Wann JPA?
Nutze JDBC für:
- Bulk-Operations (10.000+ Rows löschen)
- Komplexe Reporting-Queries
- Performance-kritische Abschnitte
Nutze JPA für:
- Enterprise-Anwendungen (90% aller Fälle!)
- CRUD-Operationen
- Komplexe Objektbeziehungen
- Weniger Code schreiben
🟢 GRUNDLAGEN: Deine erste Entity
Entity-Klasse erstellen
package com.javafleet.model;
import jakarta.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "username", nullable = false, unique = true)
private String username;
@Column(name = "email", nullable = false)
private String email;
@Column(name = "created_at")
private LocalDateTime createdAt;
// Default Constructor (PFLICHT für JPA!)
public User() {}
public User(String username, String email) {
this.username = username;
this.email = email;
}
@PrePersist
protected void onCreate() {
createdAt = LocalDateTime.now();
}
// Getters & Setters
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
public String getUsername() { return username; }
public void setUsername(String username) { this.username = username; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
public LocalDateTime getCreatedAt() { return createdAt; }
}
Annotations erklärt:
@Entity – „Diese Klasse ist eine Entity (= DB-Tabelle)“
@Table(name = „users“) – „Sie mappt zur Tabelle ‚users'“
@Id – „Das ist der Primary Key“
@GeneratedValue – „Wert wird automatisch generiert (Auto-Increment)“
@Column – „Spalten-Details: Name, Constraints“
@PrePersist – „Vor persist() ausführen (für Timestamps)“
persistence.xml konfigurieren
Speicherort: src/main/resources/META-INF/persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
version="3.0">
<persistence-unit name="myPU" transaction-type="JTA">
<jta-data-source>jdbc/myDB</jta-data-source>
<properties>
<!-- Hibernate Dialect -->
<property name="hibernate.dialect"
value="org.hibernate.dialect.MySQL8Dialect"/>
<!-- SQL-Logging (nur Development!) -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<!-- Schema-Generation -->
<property name="hibernate.hbm2ddl.auto" value="update"/>
</properties>
</persistence-unit>
</persistence>
Wichtige Properties:
hibernate.dialect – SQL-Dialekt für deine Datenbank
hibernate.show_sql – Zeigt generiertes SQL (Debug)
hibernate.hbm2ddl.auto – Schema-Management:
none– Production (nichts machen)validate– Schema prüfenupdate– Schema aktualisieren (Development)create– Schema neu erstellen (LÖSCHT DATEN!)
EntityManager nutzen

import jakarta.ejb.Stateless;
import jakarta.persistence.EntityManager;
import jakarta.persistence.PersistenceContext;
@Stateless
public class UserService {
@PersistenceContext
private EntityManager em;
// CREATE
public void createUser(String username, String email) {
User user = new User(username, email);
em.persist(user);
// INSERT beim Transaction-Commit!
}
// READ
public User findUser(Long id) {
return em.find(User.class, id);
}
// UPDATE
public void updateEmail(Long id, String newEmail) {
User user = em.find(User.class, id);
if (user != null) {
user.setEmail(newEmail);
// Automatisches UPDATE dank Dirty Checking!
}
}
// DELETE
public void deleteUser(Long id) {
User user = em.find(User.class, id);
if (user != null) {
em.remove(user);
}
}
// QUERY
public List<User> findUsersByEmail(String pattern) {
return em.createQuery(
"SELECT u FROM User u WHERE u.email LIKE :pattern",
User.class
)
.setParameter("pattern", "%" + pattern + "%")
.getResultList();
}
}
EntityManager Methoden:
persist(entity) – INSERT (Entity wird MANAGED)
find(Class, id) – SELECT per Primary Key
merge(entity) – UPDATE (Detached → Managed)
remove(entity) – DELETE
createQuery(jpql) – JPQL-Queries
🟡 PROFESSIONALS: Production-Ready Setup
DataSource konfigurieren
Im Payara Server:
- JDBC Connection Pool erstellen:
- Admin Console → Resources → JDBC → Connection Pools
- Pool Name:
MySQLPool - Database: MySQL
- Server:
localhost:3306 - Database:
jpadb - User/Password:
root/secret
- JDBC Resource erstellen:
- Admin Console → Resources → JDBC Resources
- JNDI Name:
jdbc/myDB - Pool:
MySQLPool
Warum DataSource statt hardcoded Connection?
- ✅ Connection Pooling
- ✅ Zentrale Konfiguration
- ✅ Umgebungs-spezifisch (DEV/TEST/PROD)
- ✅ Keine Credentials im Code
Hibernate Properties (Production)
<properties>
<!-- WICHTIG: In Production NIEMALS "update" oder "create"! -->
<property name="hibernate.hbm2ddl.auto" value="none"/>
<!-- Kein SQL-Logging in Production -->
<property name="hibernate.show_sql" value="false"/>
<!-- Performance -->
<property name="hibernate.jdbc.batch_size" value="20"/>
<property name="hibernate.order_inserts" value="true"/>
<!-- Cache -->
<property name="hibernate.cache.use_second_level_cache" value="true"/>
</properties>
Schema-Changes in Production: Nutze Flyway oder Liquibase, NIEMALS hbm2ddl.auto!
Transaction Management
@Stateless
public class UserService {
@PersistenceContext
private EntityManager em;
// Automatische Transaction durch @Stateless!
public void createUser(User user) {
em.persist(user);
// Commit beim Method-Ende
}
@TransactionAttribute(TransactionAttributeType.REQUIRES_NEW)
public void createUserNewTransaction(User user) {
em.persist(user);
// Eigene Transaction, unabhängig vom Caller
}
}
Rollback bei Exception:
public void createUser(User user) throws Exception {
em.persist(user);
if (user.getEmail().contains("invalid")) {
throw new Exception("Invalid email");
// Automatischer Rollback!
}
}
🔵 BONUS: Advanced Features
Lazy vs. Eager Loading
@Entity
public class User {
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders; // Nicht sofort geladen!
}
LAZY: Daten werden erst geladen wenn benötigt
EAGER: Daten werden sofort mitgeladen
Best Practice: Default belassen, bei Bedarf JOIN FETCH nutzen:
User user = em.createQuery(
"SELECT u FROM User u LEFT JOIN FETCH u.orders WHERE u.id = :id",
User.class
).setParameter("id", id).getSingleResult();
N+1 Problem vermeiden
Problem:
List<User> users = em.createQuery("SELECT u FROM User u", User.class)
.getResultList(); // 1 Query
for (User user : users) {
user.getOrders().size(); // N Queries!
}
→ Bei 100 Users: 101 Queries!
Lösung: JOIN FETCH
List<User> users = em.createQuery(
"SELECT DISTINCT u FROM User u LEFT JOIN FETCH u.orders",
User.class
).getResultList(); // Nur 1 Query!
Named Queries
@Entity
@NamedQuery(
name = "User.findByEmail",
query = "SELECT u FROM User u WHERE u.email = :email"
)
public class User { ... }
Verwendung:
User user = em.createNamedQuery("User.findByEmail", User.class)
.setParameter("email", "test@example.com")
.getSingleResult();
Vorteil: Query wird beim Start validiert, Fehler früh erkannt!
💬 Real Talk: JPA in der Praxis
Java Fleet Büro, 15:00 Uhr. Nova sitzt frustriert vor Laptop, Elyndra kommt vorbei.
Nova: „Elyndra, warum soll ich JPA lernen wenn JDBC funktioniert?“
Elyndra: „Zeig mal. Was machst du?“
Nova: „User mit Orders laden. Mit JDBC ein JOIN. Jetzt hab ich @OneToMany, LazyInitializationException… das ist Overkill!“
Elyndra (schmunzelt): „Lass mich raten – user.getOrders() außerhalb der Transaction?“
Nova: „Ja! Warum lädt JPA die Orders nicht wenn ich sie brauche?“
Elyndra: „Kann es – mit JOIN FETCH:“
em.createQuery(
"SELECT u FROM User u LEFT JOIN FETCH u.orders WHERE u.id = :id",
User.class
).setParameter("id", id).getSingleResult();
Nova: „Oh! Das ist clever. Aber warum nicht alles EAGER?“
Elyndra: „Dann lädst du 1000 Orders, auch wenn du nur den Namen brauchst. Performance-Killer!“
Nova: „Macht Sinn. Aber diese persistence.xml nervt.“
Elyndra: „Einmal Setup, dann fertig. Und du bekommst:
- Automatisches Mapping
- Dirty Checking
- Transaktionen
- Caching
- Keine SQL-Injection
Mit JDBC schreibst du 20 Zeilen pro CRUD. Mit JPA eine Zeile.“
Nova (grinst): „Lowkey überzeugt. Hibernate oder EclipseLink?“
Elyndra: „Hibernate. Bessere Community, mehr Tutorials.“
✅ Checkpoint: Hast du es verstanden?
Quiz:
Frage 1: Was ist der Hauptunterschied zwischen JDBC und JPA?
Frage 2: Welche 4 Hauptmethoden hat der EntityManager für CRUD?
Frage 3: Was bedeutet @Entity auf einer Klasse?
Frage 4: Warum braucht eine Entity einen Default Constructor?
Frage 5: Was macht @PrePersist?
Frage 6: Wann nutzt du GenerationType.IDENTITY vs. SEQUENCE?
Frage 7: Was ist „Dirty Checking“?
Frage 8: Warum sollte hibernate.hbm2ddl.auto in Production „none“ sein?
Frage 9: Was ist das N+1 Problem und wie löst du es?
Frage 10: Wann würdest du JDBC statt JPA nutzen?
🎯 Mini-Challenge
Aufgabe: Erstelle ein JPA Product-Management
Requirements:
- Entity
Product:- Auto-generated ID
- Name (max 100 Zeichen, NOT NULL)
- Price (BigDecimal, NOT NULL)
- Stock (Integer, default 0)
- CreatedAt Timestamp
- Service
ProductService:- createProduct()
- findProductById()
- findAllProducts()
- updateStock()
- deleteProduct()
- persistence.xml:
- Hibernate als Provider
- MySQL Dialect
- Auto-update für Development
- Bonus:
- @PrePersist für createdAt
- Named Query für findAll
Lösung:
Findest du am Anfang von Tag 8! 🚀
GitHub: [Link folgt]
Geschafft? 🎉
❓ Häufig gestellte Fragen
Frage 1: Muss ich für jede Tabelle eine Entity erstellen?
Für Tabellen, die du per JPA verwalten willst – ja. Aber du kannst Native SQL für komplexe Queries nutzen und DTOs für Read-Only Views.
Frage 2: Wie migriere ich von JDBC zu JPA?
Schrittweise! Phase 1: JPA parallel einführen. Phase 2: CRUD zu JPA. Phase 3: Komplexe Queries. Nicht alles auf einmal!
Frage 3: Wie teste ich JPA-Code?
Option 1: H2 In-Memory DB für Tests
Option 2: Testcontainers mit echter DB
Empfehlung: H2 für Unit-Tests, Testcontainers für Integration-Tests.
Frage 4: Wie handle ich Enums?
@Enumerated(EnumType.STRING) // Speichert "ADMIN", "USER" private UserRole role;
IMMER EnumType.STRING! Nie ORDINAL (bricht bei Reihenfolge-Änderung).
Frage 5: Kann ich andere DBs als MySQL nutzen?
Klar! JPA ist datenbank-agnostisch. Nur Dialect ändern:
<!-- PostgreSQL -->
<property name="hibernate.dialect"
value="org.hibernate.dialect.PostgreSQLDialect"/>
Frage 6: Wie handle ich Optimistic Locking?
@Version private int version; // JPA verwaltet automatisch!
Bei Concurrent Updates wirft JPA OptimisticLockException.
Frage 7: Bernd meinte, „JPA ist overthinking für simple Apps“. Recht?
Lowkey ja für 3-Tabellen-Apps. Aber sobald du 10+ Tabellen, Relationen und Business-Logik hast, zahlt sich JPA aus. In Enterprise-Projekten ist JPA Standard.
Real talk: Upfront mehr Setup, langfristig weniger Arbeit. Für Production fast immer besser.
Jakarta Web Aufbau - Tag 7
Tag 7 Quiz
🎉 Tag 7 geschafft!
Slay! Du hast es geschafft! 🚀
Das hast du heute gerockt:
- ✅ JPA vs JDBC verstanden
- ✅ persistence.xml konfiguriert
- ✅ Erste Entity erstellt
- ✅ EntityManager CRUD gemeistert
- ✅ Production-Ready Setup gelernt
Von JDBC-Queries zu automatischem ORM!
Main Character Energy: Unlocked! ✨
Real talk:
JPA ist am Anfang overwhelming – aber du hast es geschafft! Das ist ein massiver Skill-Boost für deine Karriere.
🚀 Wie geht’s weiter?
Morgen (Tag 8): JPA Relationen (1): @OneToOne & @ManyToOne
Was dich erwartet:
- Relationen zwischen Entities (@OneToOne, @ManyToOne)
- Foreign Keys und JOINs
- Bidirektionale Relationen
- Cascade-Types – dein Durchbruch für komplexe Domain-Modelle! 🔥
Brauchst du eine Pause?
Absolut! JPA ist intensive Kost. Lass es sacken, spiel mit Entities.
Tipp für heute Abend:
Erweitere die User-Entity:
- Füge Role-Enum hinzu
- Erstelle Named Queries
- Teste alle CRUD-Operationen
Learning by doing! 🔧
🔧 Troubleshooting
Problem: LazyInitializationException
Ursache: LAZY Collection außerhalb Transaction.
Lösung: JOIN FETCH oder FetchType.EAGER
Problem: No Persistence provider
Ursache: Hibernate nicht gefunden.
Lösung:
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
Prüfe: persistence.xml unter META-INF/!
Problem: Table doesn’t exist
Lösung Development:
<property name="hibernate.hbm2ddl.auto" value="update"/>
Production: Tabelle manuell erstellen oder Flyway nutzen!
📚 Resources & Links
Offizielle Docs:
- Jakarta Persistence: https://jakarta.ee/specifications/persistence/
- Hibernate ORM: https://hibernate.org/orm/documentation/
Tutorials:
- Baeldung JPA: https://www.baeldung.com/jpa-hibernate-guide
- Thorben Janssen: https://thorben-janssen.com/tips/
Books:
- „Pro JPA 2“ by Mike Keith
- „High-Performance Java Persistence“ by Vlad Mihalcea (must-read!)
💬 Feedback?
War Tag 7 zu theoretisch? Mehr Praxis gewünscht?
Bis morgen! 👋
Elyndra
elyndra@java-developer.online
Senior Developer bei Java Fleet Systems Consulting
Java Web Aufbau – Tag 7 von 10
© 2025 Java Fleet Systems Consulting
Website: java-developer.online